The status quo
Back in 2015, I bought an off-the-shelf NAS, a QNAP TS-453mini, to act as my file store and Plex server. I had previously owned a Synology box, and whilst I liked the Synology OS and experience, the hardware was underwhelming. I loaded up the successor QNAP with four 5TB drives in RAID10, and moved all my files over (after some initial DoA drive issues were handled).
QNAP TS-453mini product photo
That thing has been in service for about 8 years now, and it s been a mixed bag. It was definitely more powerful than the predecessor system, but it was clear that QNAP s OS was not up to the same standard as Synology s perhaps best exemplified by HappyGet 2 , the QNAP webapp for downloading videos from streaming services like YouTube, whose icon is a straight rip-off of StarCraft 2. On its own, meaningless but a bad omen for overall software quality
The logo for QNAP HappyGet 2 and Blizzard s StarCraft 2 side by side
Additionally, the embedded Celeron processor in the NAS turned out to be an issue for some cases. It turns out, when playing back videos with subtitles, most Plex clients do not support subtitles properly instead they rely on the Plex server doing JIT transcoding to bake the subtitles directly into the video stream. I discovered this with some Blu-Ray rips of Game of Thrones some episodes would play back fine on my smart TV, but episodes with subtitled Dothraki speech would play at only 2 or 3 frames per second.
The final straw was a ransomware attack, which went through all my data and locked every file below a 60MiB threshold. Practically all my music gone. A substantial collection of downloaded files, all gone. Some of these files had been carried around since my college days digital rarities, or at least digital detritus I felt a real sense of loss at having to replace. This episode was caused by a ransomware targeting specific vulnerabilities in the QNAP OS, not an error on my part.
So, I decided to start planning a replacement with:
A non-garbage OS, whilst still being a NAS-appliance type offering (not an off-the-shelf Linux server distro)
Full remote management capabilities
A small form factor comparable to off-the-shelf NAS
A powerful modern CPU capable of transcoding high resolution video
All flash storage, no spinning rust
At the time, no consumer NAS offered everything (The Asustor FS6712X exists now, but didn t when this project started), so I opted to go for a full DIY rather than an appliance not the first time I ve jumped between appliances and DIY for home storage.
Selecting the core of the system
There aren t many companies which will sell you a small motherboard with IPMI. Supermicro is a bust, so is Tyan. But ASRock Rack, the server division of third-tier motherboard vendor ASRock, delivers. Most of their boards aren t actually compliant Mini-ITX size, they re a proprietary Deep Mini-ITX with the regular screw holes, but 40mm of extra length (and a commensurately small list of compatible cases). But, thankfully, they do have a tiny selection of boards without the extra size, and I stumbled onto the X570D4I-2T, a board with an AMD AM4 socket and the mature X570 chipset. This board can use any AMD Ryzen chip (before the latest-gen Ryzen 7000 series); has built in dual 10 gigabit ethernet; IPMI; four (laptop-sized) RAM slots with full ECC support; one M.2 slot for NVMe SSD storage; a PCIe 16x slot (generally for graphics cards, but we live in a world of possibilities); and up to 8 SATA drives OR a couple more NVMe SSDs. It s astonishingly well featured, just a shame it costs about $450 compared to a good consumer-grade Mini ITX AM4 board costing less than half that.
I was so impressed with the offering, in fact, that I crowed about it on Mastodon and ended up securing ASRock another sale, with someone else looking into a very similar project to mine around the same timespan.
The next question was the CPU. An important feature of a system expected to run 24/7 is low power, and AM4 chips can consume as much as 130W under load, out of the box. At the other end, some models can require as little as 35W under load the OEM-only GE suffix chips, which are readily found for import on eBay. In their PRO variant, they also support ECC (all non-G Ryzen chips support ECC, but only Pro G chips do). The top of the range 8 core Ryzen 7 PRO 5750GE is prohibitively expensive, but the slightly weaker 6 core Ryzen 5 PRO 5650GE was affordable, and one arrived quickly from Hong Kong. Supplemented with a couple of cheap 16 GiB SODIMM sticks of DDR4 PC-3200 direct from Micron for under $50 a piece, that left only cooling as an unsolved problem to get a bootable test system.
The official support list for the X570D4I-2T only includes two rackmount coolers, both expensive and hard to source. The reason for such a small list is the non standard cooling layout of the board instead of an AM4 hole pattern with the standard plastic AM4 retaining clips, it has an Intel 115x hole pattern with a non-standard backplate (Intel 115x boards have no backplate, the stock Intel 115x cooler attaches to the holes with push pins). As such every single cooler compatibility list excludes this motherboard. However, the backplate is only secured with a mild glue with minimal pressure and a plastic prying tool it can be removed, giving compatibility with any 115x cooler (which is basically any CPU cooler for more than a decade). I picked an oversized low profile Thermalright AXP120-X67 hoping that its 120mm fan would cool the nearby MOSFETs and X570 chipset too.
Thermalright AXP120-X67, AMD Ryzen 5 PRO 5650GE, ASRock Rack X570D4I-2T, all assembled and running on a flat surface
Testing up to this point
Using a spare ATX power supply, I had enough of a system built to explore the IPMI and UEFI instances, and run MemTest86 to validate my progress. The memory test ran without a hitch and confirmed the ECC was working, although it also showed that the memory was only running at 2933 MT/s instead of the rated 3200 MT/s (a limit imposed by the motherboard, as higher speeds are considered overclocking). The IPMI interface isn t the best I ve ever used by a long shot, but it s minimum viable and allowed me to configure the basics and boot from media entirely via a Web browser.
Memtest86 showing test progress, taken from IPMI remote control window
One sad discovery, however, which I ve never seen documented before, on PCIe bifurcation.
With PCI Express, you have a number of lanes which are allocated in groups by the motherboard and CPU manufacturer. For Ryzen prior to Ryzen 7000, that s 16 lanes in one slot for the graphics card; 4 lanes in one M.2 connector for an SSD; then 4 lanes connecting the CPU to the chipset, which can offer whatever it likes for peripherals or extra lanes (bottlenecked by that shared 4x link to the CPU, if it comes down to it).
It s possible, with motherboard and CPU support, to split PCIe groups up for example an 8x slot could be split into two 4x slots (eg allowing two NVMe drives in an adapter card NVME drives these days all use 4x). However with a Cezanne Ryzen with integrated graphics, the 16x graphics card slot cannot be split into four 4x slots (ie used for for NVMe drives) the most bifurcation it allows is 8x4x4x, which is useless in a NAS.
Screenshot of PCIe 16x slot bifurcation options in UEFI settings, taken from IPMI remote control window
As such, I had to abandon any ideas of an all-NVMe NAS I was considering: the 16x slot split into four 4x, combined with two 4x connectors fed by the X570 chipset, to a total of 6 NVMe drives. 7.6TB U.2 enterprise disks are remarkably affordable (cheaper than consumer SATA 8TB drives), but alas, I was locked out by my 5650GE. Thankfully I found out before spending hundreds on a U.2 hot swap bay. The NVMe setup would be nearly 10x as fast as SATA SSDs, but at least the SATA SSD route would still outperform any spinning rust choice on the market (including the fastest 10K RPM SAS drives)
Containing the core
The next step was to pick a case and power supply. A lot of NAS cases require an SFX (rather than ATX) size supply, so I ordered a modular SX500 unit from Silverstone. Even if I ended up with a case requiring ATX, it s easy to turn an SFX power supply into ATX, and the worst result is you have less space taken up in your case, hardly the worst problem to have.
That said, on to picking a case. There s only one brand with any cachet making ITX NAS cases, Silverstone. They have three choices in an appropriate size: CS01-HS, CS280, and DS380. The problem is, these cases are all badly designed garbage. Take the CS280 as an example, the case with the most space for a CPU cooler. Here s how close together the hotswap bay (right) and power supply (left) are:
Internal image of Silverstone CS280 NAS build. Image stolen from ServeTheHome
With actual cables connected, the cable clearance problem is even worse:
Internal image of Silverstone CS280 NAS build. Image stolen from ServeTheHome
Remember, this is the best of the three cases for internal layout, the one with the least restriction on CPU cooler height. And it s garbage! Total hot garbage! I decided therefore to completely skip the NAS case market, and instead purchase a 5.25 -to-2.5 hot swap bay adapter from Icy Dock, and put it in an ITX gamer case with a 5.25 bay. This is no longer a served market 5.25 bays are extinct since nobody uses CD/DVD drives anymore. The ones on the market are really new old stock from 2014-2017: The Fractal Design Core 500, Cooler Master Elite 130, and Silverstone SUGO 14. Of the three, the Fractal is the best rated so I opted to get that one however it seems the global supply of new old stock fully dried up in the two weeks between me making a decision and placing an order leaving only the Silverstone case.
Icy Dock have a selection of 8-bay 2.5 SATA 5.25 hot swap chassis choices in their ToughArmor MB998 series. I opted for the ToughArmor MB998IP-B, to reduce cable clutter it requires only two SFF-8611-to-SF-8643 cables from the motherboard to serve all eight bays, which should make airflow less of a mess. The X570D4I-2T doesn t have any SATA ports on board, instead it has two SFF-8611 OCuLink ports, each supporting 4 PCI Express lanes OR 4 SATA connectors via a breakout cable. I had hoped to get the ToughArmor MB118VP-B and run six U.2 drives, but as I said, the PCIe bifurcation issue with Ryzen G chips meant I wouldn t be able to run all six bays successfully.
NAS build in Silverstone SUGO 14, mid build, panels removedSilverstone SUGO 14 from the front, with hot swap bay installed
Actual storage for the storage server
My concept for the system always involved a fast boot/cache drive in the motherboard s M.2 slot, non-redundant (just backups of the config if the worst were to happen) and separate storage drives somewhere between 3.8 and 8 TB each (somewhere from $200-$350). As a boot drive, I selected the Intel Optane SSD P1600X 58G, available for under $35 and rated for 228 years between failures (or 11,000 complete drive rewrite cycles).
So, on to the big expensive choice: storage drives. I narrowed it down to two contenders: new-old-stock Intel D3-S4510 3.84TB enterprise drives, at about $200, or Samsung 870 QVO 8TB consumer drives, at about $375. I did spend a long time agonizing over the specification differences, the ZFS usage reports, the expected lifetime endurance figures, but in reality, it came down to price $1600 of expensive drives vs $3200 of even more expensive drives. That s 27TB of usable capacity in RAID-Z1, or 23TB in RAID-Z2. For comparison, I m using about 5TB of the old NAS, so that s a LOT of overhead for expansion.
Storage SSD loaded into hot swap sled
Booting up
Bringing it all together is the OS. I wanted an appliance NAS OS rather than self-administering a Linux distribution, and after looking into the surrounding ecosystems, decided on TrueNAS Scale (the beta of the 2023 release, based on Debian 12).
TrueNAS Dashboard screenshot in browser window
I set up RAID-Z1, and with zero tuning (other than enabling auto-TRIM), got the following performance numbers:
Finally, the numbers reported on the old NAS with four 7200 RPM hard disks in RAID 10:
IOPS
Bandwidth
4k random writes
430
1.7 MiB/s
4k random reads
8006
32 MiB/s
Sequential writes
311 MiB/s
Sequential reads
566 MiB/s
Performance seems pretty OK. There s always going to be an overhead to RAID. I ll settle for the 45x improvement on random writes vs. its predecessor, and 4.5x improvement on random reads. The sequential write numbers are gonna be impacted by the size of the ZFS cache (50% of RAM, so 16 GiB), but the rest should be a reasonable indication of true performance.
It took me a little while to fully understand the TrueNAS permissions model, but I finally got Plex configured to access data from the same place as my SMB shares, which have anonymous read-only access or authenticated write access for myself and my wife, working fine via both Linux and Windows.
And that s it! I built a NAS. I intend to add some fans and more RAM, but that s the build. Total spent: about $3000, which sounds like an unreasonable amount, but it s actually less than a comparable Synology DiskStation DS1823xs+ which has 4 cores instead of 6, first-generation AMD Zen instead of Zen 3, 8 GiB RAM instead of 32 GiB, no hardware-accelerated video transcoding, etc. And it would have been a whole lot less fun!
The final system, powered up
(Also posted on PCPartPicker)
Two years ago, I wrote Managing an External Display on Linux Shouldn t Be This Hard. Happily, since I wrote that post, most of those issues have been resolved.
But then you throw HiDPI into the mix and it all goes wonky.
If you re running X11, basically the story is that you can change the scale factor, but it only takes effect on newly-launched applications (which means a logout/in because some of your applications you can t really re-launch). That is a problem if, like me, you sometimes connect an external display that is HiDPI, sometimes not, or your internal display is HiDPI but others aren t. Wayland is far better, supporting on-the-fly resizes quite nicely.
I ve had two devices with HiDPI displays: a Surface Go 2, and a work-issued Thinkpad. The Surface Go 2 is my ultraportable Linux tablet. I use it sparingly at home, and rarely with an external display. I just put Gnome on it, in part because Gnome had better on-screen keyboard support at the time, and left it at that.
On the work-issued Thinkpad, I really wanted to run KDE thanks to its tiling support (I wound up using bismuth with it). KDE was buggy with Wayland at the time, so I just stuck with X11 and ran my HiDPI displays at lower resolutions and lived with the fuzziness.
But now that I have a Framework laptop with a HiDPI screen, I wanted to get this right.
I tried both Gnome and KDE. Here are my observations with both:
Gnome
I used PaperWM with Gnome. PaperWM is a tiling manager with a unique horizontal ribbon approach. It grew on me; I think I would be equally at home, or maybe even prefer it, to my usual xmonad-style approach. Editing the active window border color required editing ~/.local/share/gnome-shell/extensions/paperwm@hedning:matrix.org/stylesheet.css and inserting background-color and border-color items in the paperwm-selection section.
Gnome continues to have an absolutely terrible picture for configuring things. It has no less than four places to make changes (Settings, Tweaks, Extensions, and dconf-editor). In many cases, configuration for a given thing is split between Settings and Tweaks, and sometimes even with Extensions, and then there are sometimes options that are only visible in dconf. That is, where the Gnome people have even allowed something to be configurable.
Gnome installs a power manager by default. It offers three options: performance, balanced, and saver. There is no explanation of the difference between them. None. What is it setting when I change the pref? A maximum frequency? A scaling governor? A balance between performance and efficiency cores? Not only that, but there s no way to tell it to just use performance when plugged in and balanced or saver when on battery. In an issue about adding that, a Gnome dev wrote We re not going to add a preference just because you want one . KDE, on the other hand, aside from not mucking with your system s power settings in this way, has a nice panel with on AC and on battery and you can very easily tweak various settings accordingly. The hostile attitude from the Gnome developers in that thread was a real turnoff.
While Gnome has excellent support for Wayland, it doesn t (directly) support fractional scaling. That is, you can set it to 100%, 200%, and so forth, but no 150%. Well, unless you manage to discover that you can run gsettings set org.gnome.mutter experimental-features "['scale-monitor-framebuffer']" first. (Oh wait, does that make a FIFTH settings tool? Why yes it does.) Despite its name, that allows you to select fractional scaling under Wayland. For X11 apps, they will be blurry, a problem that is optional under KDE (more on that below).
Gnome won t show the battery life time remaining on the task bar. Yikes. An extension might work in some cases. Not only that, but the Gnome battery icon frequently failed to indicate AC charging when AC was connected, a problem that didn t exist on KDE.
Both Gnome and KDE support night light (warmer color temperatures at night), but Gnome s often didn t change when it should have, or changed on one display but not the other.
The appindicator extension is pretty much required, as otherwise a number of applications (eg, Nextcloud) don t have their icon display anywhere. It does, however, generate a significant amount of log spam. There may be a fix for this.
Unlike KDE, which has a nice inobtrusive popup asking what to do, Gnome silently automounts USB sticks when inserted. This is often wrong; for instance, if I m about to dd a Debian installer to it, I definitely don t want it mounted. I learned this the hard way. It is particularly annoying because in a GUI, there is no reason to mount a drive before the user tries to access it anyhow. It looks like there is a dconf setting, but then to actually mount a drive you have to open up Files (because OF COURSE Gnome doesn t have a nice removable-drives icon like KDE does) and it s a bunch of annoying clicks, and I didn t want to use the GUI file manager anyway. Same for unmounting; two clicks in KDE thanks to the task bar icon, but in Gnome you have to open up the file manager, unmount the drive, close the file manager again, etc.
The ssh agent on Gnome doesn t start up for a Wayland session, though this is easily enough worked around.
The reason I completely soured on Gnome is that after using it for awhile, I noticed my laptop fans spinning up. One core would be constantly busy. It was busy with a kworker events task, something to do with sound events. Logging out would resolve it. I believe it to be a Gnome shell issue. I could find no resolution to this, and am unwilling to tolerate the decreased battery life this implies.
The Gnome summary: it looks nice out of the box, but you quickly realize that this is something of a paper-thin illusion when you try to actually use it regularly.
KDE
The KDE experience on Wayland was a little bit opposite of Gnome. While with Gnome, things start out looking great but you realize there are some serious issues (especially battery-eating), with KDE things start out looking a tad rough but you realize you can trivially fix them and wind up with a very solid system.
Compared to Gnome, KDE never had a battery-draining problem. It will show me estimated battery time remaining if I want it to. It will do whatever I want it to when I insert a USB drive. It doesn t muck with my CPU power settings, and lets me easily define on AC vs on battery settings for things like suspend when idle.
KDE supports fractional scaling, to any arbitrary setting (even with the gsettings thing above, Gnome still only supports it in 25% increments). Then the question is what to do with X11-only applications. KDE offers two choices. The first is Scaled by the system , which is also the only option for Gnome. With that setting, the X11 apps effectively run natively at 100% and then are scaled up within Wayland, giving them a blurry appearance on HiDPI displays. The advantage is that the scaling happens within Wayland, so the size of the app will always be correct even when the Wayland scaling factor changes. The other option is Apply scaling themselves , which uses native X11 scaling. This lets most X11 apps display crisp and sharp, but then if the system scaling changes, due to limitations of X11, you ll have to restart the X apps to get them to be the correct size. I appreciate the choice, and use Apply scaling by themselves because only a few of my apps aren t Wayland-aware.
I did encounter a few bugs in KDE under Wayland:
sddm, the display manager, would be slow to stop and cause a long delay on shutdown or reboot. This seems to be a known issue with sddm and Wayland, and is easily worked around by adding a systemd TimeoutStopSec.
Konsole, the KDE terminal emulator, has weird display artifacts when using fractional scaling under Wayland. I applied some patches and rebuilt Konsole and then all was fine.
The Bismuth tiling extension has some pretty weird behavior under Wayland, but a 1-character patch fixes it.
On Debian, KDE mysteriously installed Pulseaudio instead of Debian s new default Pipewire, but that was easily fixed as well (and Pulseaudio also works fine).
Conclusions
I m sticking with KDE. Given that I couldn t figure out how to stop Gnome from deciding to eat enough battery to make my fan come on, the decision wasn t hard. But even if it weren t for that, I d have gone with KDE. Once a couple of things were patched, the experience is solid, fast, and flawless. Emacs (my main X11-only application) looks great with the self-scaling in KDE. Gimp, which I use occasionally, was terrible with the blurry scaling in Gnome.
Update: Corrected the gsettings command
I m happy to announce that Netplan version 0.107 is now available on GitHub and is soon to be deployed into a Linux installation near you! Six months and more than 200 commits after the previous version (including a .1 stable release), this release is brought to you by 8 free software contributors from around the globe.
Highlights
Highlights of this release include the new configuration types for veth and dummy interfaces:
Furthermore, we implemented CFFI based Python bindings on top of libnetplan s API, that can easily be consumed by 3rd party applications (see full cffi-bindings.py example):
from netplan import Parser, State, NetDefinition
from netplan import NetplanException, NetplanParserException
parser = Parser()
# Parse the full, existing YAML config hierarchy
parser.load_yaml_hierarchy(rootdir='/')
# Validate the final parser state
state = State()
try:
# validation of current state + new settings
state.import_parser_results(parser)
except NetplanParserException as e:
print('Error in', e.filename, 'Row/Col', e.line, e.column, '->', e.message)
except NetplanException as e:
print('Error:', e.message)
# Walk through ethernet NetdefIDs in the state and print their backend
# renderer, to demonstrate working with NetDefinitionIterator &
# NetDefinition
for netdef in state.ethernets.values():
print('Netdef', netdef.id, 'is managed by:', netdef.backend)
print('Is it configured to use DHCP?', netdef.dhcp4 or netdef.dhcp6)
Taking a hands-on low-level approach to learning AI has been
incredibly rewarding. I wanted to create an achievable task that would
motivate me to learn the tools and get practical experience training and
using large language models. Just at the point when I was starting to
spin up GPU instances, Llama2 was released to the public. So I elected
to start with that model. As I mentioned, I m
interested in exploring how sex-positive AI can help human connection in
positive ways. For that reason, I suspected that Llama2 might not
produce good results without training: some of Meta s safety goals run
counter to what I m trying to explore. I suspected that there might be
more attention paid to safety in the chat variants of Llama2 rather than
the text generation variants, and working against that might be
challenging for a first project, so I started with Llama-2-13b as a
base.
Preparing a Dataset
I elected to generate a fine tuning dataset using fiction. Long term,
that might not be a good fit. But I ve always wanted to understand how
an LLM s tone is adjusted how you get an LLM to speak in a different
voice. So much of fine tuning focuses on examples where a given prompt
produces a particular result. I wanted to understand how to bring in
data that wasn t structured as prompts. The Huggingface course actually
gives an example of how to adjust a model set up for masked language
modeling trained on wikitext to be better at predicting the vocabulary
of movie reviews. There though, doing sample breaks in the dataset at
movie review boundaries makes sense. There s another example of training
an LLM from scratch based on a corpus of python code. Between these two
examples, I figured out what I needed. It was relatively simple in
retrospect: tokenize the whole mess, and treat everything as output.
That is, compute loss on all the tokens.
Long term, using fiction as a way to adjust how the model responds is
likely to be the wrong starting point. However, it maximized focus on
aspects of training I did not understand and allowed me to satisfy my
curiosity.
Rangling the Model
I decided to actually try and add additional training to the model
directly rather than building an adapter and fine tuning a small number
of parameters. Partially this was because I had enough on my mind
without understanding how LoRA adapters work. Partially, I wanted to
gain an appreciation for the infrastructure complexity of AI training. I
have enough of a cloud background that I ought to be able to work on
distributed training. (As it turned out, using BitsAndBytes 8-bit
optimizer, I was just able to fit my task onto a single GPU).
I wasn t even sure that I could make a measurable difference in
Llama-2-13b running 890,000 training tokens through a couple of training
epochs. As it turned out I had nothing to fear on that front.
Getting everything to work was more tricky than I expected. I didn t
have an appreciation for exactly how memory intensive training was. The
Transformers documentation points out that with typical parameters for
mixed-precision training, it takes 18 bytes per model parameter. Using
bfloat16 training and an 8-bit optimizer was enough to get things to
fit.
Of course then I got to play with convergence. My initial optimizer
parameters caused the model to diverge, and before I knew it, my model
had turned to NAN, and would only output newlines. Oops. But looking
back over the logs, watching what happened to the loss, and looking at
the math in the optimizer to understand how I ended up getting something
that rounded to a divide by zero gave me a much better intuition for
what was going on.
The results.
This time around I didn t do anything in the way of quantitative
analysis of what I achieved. Empirically I definitely changed the tone
of the model. The base Llama-2 model tends to steer away from sexual
situations. It s relatively easy to get it to talk about affection and
sometimes attraction. Unsurprisingly, given the design constraints, it
takes a bit to get it to wonder into sexual situations. But if you hit
it hard enough with your prompt, it will go there, and the results are
depressing. At least for prompts I used, it tended to view sex fairly
negatively. It tended to be less coherent than with other prompts. One
inference managed to pop out in the middle of some text that wasn t
hanging together well, Chapter 7 - Rape.
With my training, I did manage to achieve my goal of getting the
model to use more positive language and emotional signaling when talking
about sexual situations. More importantly, I gained a practical
understanding of many ways training can go wrong.
There were overfitting problems: names of characters from my
dataset got more attention than I wished they did. As a model for
interacting with some of the universes I used as input, that was kind of
cool, but if I was looking to just adjust how the model talked about
intimate situations, I massively got things to be too specific.
I gained a new appreciation for how easy it is to trigger
catastrophic forgetting.
I begin to appreciate how this sort of unsupervised training
could be best paired with supervised training to help correct model
confusion. Playing with the model, I often ran into cases where my
reaction was like Well, I don t want to train it to give that response,
but if it ever does wander into this part of the state space, I d like
to at least get it to respond more naturally. And I think I understand
how to approach that either with custom loss functions or manipulating
which tokens compute loss and which ones do not.
And of course realized I need to learn a lot about sanitizing and
preparing datasets.
A lot of articles I ve been reading about training make more sense. I
have better intuition for why you might want to do training a certain
way, or why mechanisms for countering some problem will be
important.
Future Activities:
Look into LoRA adapters; having understood what happens when you
manipulate the model directly, I can now move on to intelligent
solutions.
Look into various mechanisms for rewards and supervised
training.
See how hard it is to train a chat based model out of some of its
safety constraints.
Construct datasets; possibly looking at sources like relationship
questions/advice.
I dug out a computer running Fedora 28, which was released 2018-04-01 - over 5 years ago. Backing up the data and re-installing seemed tedious, but the current version of Fedora is 38, and while Fedora supports updates from N to N+2 that was still going to be 5 separate upgrades. That seemed tedious, so I figured I'd just try to do an update from 28 directly to 38. This is, obviously, extremely unsupported, but what could possibly go wrong?
Running sudo dnf system-upgrade download --releasever=38 didn't successfully resolve dependencies, but sudo dnf system-upgrade download --releasever=38 --allowerasing passed and dnf started downloading 6GB of packages. And then promptly failed, since I didn't have any of the relevant signing keys. So I downloaded the fedora-gpg-keys package from F38 by hand and tried to install it, and got a signature hdr data: BAD, no. of bytes(88084) out of range error. It turns out that rpm doesn't handle cases where the signature header is larger than a few K, and RPMs from modern versions of Fedora. The obvious fix would be to install a newer version of rpm, but that wouldn't be easy without upgrading the rest of the system as well - or, alternatively, downloading a bunch of build depends and building it. Given that I'm already doing all of this in the worst way possible, let's do something different.
The relevant code in the hdrblobRead function of rpm's lib/header.c is: int32_t il_max = HEADER_TAGS_MAX; int32_t dl_max = HEADER_DATA_MAX;
if (regionTag == RPMTAG_HEADERSIGNATURES) il_max = 32; dl_max = 8192;
which indicates that if the header in question is RPMTAG_HEADERSIGNATURES, it sets more restrictive limits on the size (no, I don't know why). So I installed rpm-libs-debuginfo, ran gdb against librpm.so.8, loaded the symbol file, and then did disassemble hdrblobRead. The relevant chunk ends up being: 0x000000000001bc81 <+81>: cmp $0x3e,%ebx 0x000000000001bc84 <+84>: mov $0xfffffff,%ecx 0x000000000001bc89 <+89>: mov $0x2000,%eax 0x000000000001bc8e <+94>: mov %r12,%rdi 0x000000000001bc91 <+97>: cmovne %ecx,%eax
which is basically "If ebx is not 0x3e, set eax to 0xffffffff - otherwise, set it to 0x2000". RPMTAG_HEADERSIGNATURES is 62, which is 0x3e, so I just opened librpm.so.8 in hexedit, went to byte 0x1bc81, and replaced 0x3e with 0xfe (an arbitrary invalid value). This has the effect of skipping the if (regionTag == RPMTAG_HEADERSIGNATURES) code and so using the default limits even if the header section in question is the signatures. And with that one byte modification, rpm from F28 would suddenly install the fedora-gpg-keys package from F38. Success!
But short-lived. dnf now believed packages had valid signatures, but sadly there were still issues. A bunch of packages in F38 had files that conflicted with packages in F28. These were largely Python 3 packages that conflicted with Python 2 packages from F28 - jumping this many releases meant that a bunch of explicit replaces and the like no longer existed. The easiest way to solve this was simply to uninstall python 2 before upgrading, and avoiding the entire transition. Another issue was that some data files had moved from libxcrypt-common to libxcrypt, and removing libxcrypt-common would remove libxcrypt and a bunch of important things that depended on it (like, for instance, systemd). So I built a fake empty package that provided libxcrypt-common and removed the actual package. Surely everything would work now?
Ha no. The final obstacle was that several packages depended on rpmlib(CaretInVersions), and building another fake package that provided that didn't work. I shouted into the void and Bill Nottingham answered - rpmlib dependencies are synthesised by rpm itself, indicating that it has the ability to handle extensions that specific packages are making use of. This made things harder, since the list is hard-coded in the binary. But since I'm already committing crimes against humanity with a hex editor, why not go further? Back to editing librpm.so.8 and finding the list of rpmlib() dependencies it provides. There were a bunch, but I couldn't really extend the list. What I could do is overwrite existing entries. I tried this a few times but (unsurprisingly) broke other things since packages depended on the feature I'd overwritten. Finally, I rewrote rpmlib(ExplicitPackageProvide) to rpmlib(CaretInVersions) (adding an extra '\0' at the end of it to deal with it being shorter than the original string) and apparently nothing I wanted to install depended on rpmlib(ExplicitPackageProvide) because dnf finished its transaction checks and prompted me to reboot to perform the update. So, I did.
And about an hour later, it rebooted and gave me a whole bunch of errors due to the fact that dbus never got started. A bit of digging revealed that I had no /etc/systemd/system/dbus.service, a symlink that was presumably introduced at some point between F28 and F38 but which didn't get automatically added in my case because well who knows. That was literally the only thing I needed to fix up after the upgrade, and on the next reboot I was presented with a gdm prompt and had a fully functional F38 machine.
You should not do this. I should not do this. This was a terrible idea. Any situation where you're binary patching your package manager to get it to let you do something is obviously a bad situation. And with hindsight performing 5 independent upgrades might have been faster. But that would have just involved me typing the same thing 5 times, while this way I learned something. And what I learned is "Terrible ideas sometimes work and so you should definitely act upon them rather than doing the sensible thing", so like I said, you should not do this in case you learn the same lesson.
I wrote
about how I m exploring the role of AI in human connection and intimacy.
The first part of that journey has been all about learning the software
and tools for approaching large language models.
The biggest thing I wish I had known going in was not to focus on the
traditional cloud providers. I was struggling until I found runpod.io. I kind of assumed that if you
were willing to pay for it and had the money, you could go to Amazon on
or google or whatever and get the compute resources you needed. Not so
much. Google completely rejected my request to have the maximum number
of GPUs I could run raised above a limit of 0. Go talk to your sales
representative. And of course no sales representative was willing to
waste their time on me. But I did eventually find some of the smaller
AI-specific clouds.
I intentionally wanted to run software myself. Everyone has various
fine-tuning and training APIs as well as APIs for inference. I thought
I d gain a much better understanding if I wrote my own code. That
definitely ended up being true. I started by understanding PyTorch and
the role of optimizers, gradient descent and what a model is. Then I
focused on Transformers and that ecosystem, including Accelerate,
tokenizers, generation and training.
I m really impressed with the Hugging Face ecosystem. A lot of
academic software is very purpose built and is hard to reuse and
customize. But the hub strikes an amazing balance between providing
abstractions for common interfaces like consuming a model or datasets
without getting in the way of hacking on models or evolving the
models.
I had a great time, and after a number of false starts, succeeded in
customizing Llama2 to explore some of the questions on my mind. I ll
talk about what I accomplished and learned in the next post.
KDE Akademy 2023
A big thank you goes out to the Ubuntu Community for making my attendance to the KDE Akademy 2023! This was a very successful conference for me. I had very positive feedback for my speech on A million reasons why snaps are important. I also had a productive BoF on snapping KDE applications. Most importantly I got to catch up with many old and new friends and got to put faces to the new. There were so many great talks and BoFs, but one of my favorites was the Goals as all three compliment each other. The keynote was amazing, I had no idea open source has made its way into space! How cool is that!?! Despite the high temperatures ( something I am used to, but not that humidity! ) I had a wonderful time and was able to visit many cool sites in Greece. What an amazing place.
In the snap world I haven t had much time this month as previous months as my part time gig doing them expired a few months ago and I had to focus on some paid work which has now run out. However, I did finish a new content pack containing KDE frameworks 5.108 and Qt 5.15.10 and most of KDE release applications 23.04.2. I also got Konsole working!
KDE Konsole snap
I have some fixes merged into snapcraft that will fix some strange build errors reported on the forums and for myself as well. I will be creating a new PR for the new content pack as soon as testing is complete.
We will have some very exciting news coming as soon as the t s are crossed and the i s are dotted. Until then I must reach out to the community for help to Keep the lights on until more paid work comes in. If it wasn t for all of you I couldn t make all of this possible and I thank each and every one of you. This is the greatest software community ever!
https://gofund.me/018ddb06
This post describes how to deploy cilium (and
hubble) using docker on a Linux system with
k3d or kind to test it as
CNI and
Service Mesh.
I wrote some scripts to do a local installation and evaluate cilium to use it
at work (in fact we are using cilium on an EKS
cluster now), but I thought it would be a good idea to share my original
scripts in this blog just in case they are useful to somebody, at least for
playing a little with the technology.
LinksAs there is no point on explaining here all the concepts related to cilium
I m providing some links for the reader interested on reading about it:
All the scripts and configuration files discussed in this post are available on
my cilium-docker git repository.
InstallationFor each platform we are going to deploy two clusters on the same docker
network; I ve chosen this model because it allows the containers to see the
addresses managed by metallb from both clusters (the idea
is to use those addresses for load balancers and treat them as if they were
public).
The installation(s) use cilium as CNI, metallb for BGP (I tested the
cilium options, but I wasn t able to configure them right) and nginx as the
ingress controller (again, I tried to use cilium but something didn t work
either).
To be able to use the previous components some default options have been
disabled on k3d and kind and, in the case of k3d, a lot of k3s options
(traefik, servicelb, kubeproxy, network-policy, ) have also been
disabled to avoid conflicts.
To use the scripts we need to install cilium, docker, helm, hubble,
k3d, kind, kubectl and tmpl in our system.
After cloning the repository, the sbin/tools.sh
script can be used to do that on a linux-amd64 system:
Once we have the tools, to install everything on k3d (for kind replace
k3d by kind) we can use the
sbin/cilium-install.sh script as
follows:
$# Deploy first k3d cluster with cilium & cluster-mesh$./sbin/cilium-install.sh k3d 1 full
[...]
$# Deploy second k3d cluster with cilium & cluster-mesh$./sbin/cilium-install.sh k3d 2 full
[...]
$# The 2nd cluster-mesh installation connects the clusters
If we run the command cilium status after the installation we should get an
output similar to the one seen on the following screenshot:
The installation script uses the following templates:
tmpl/cilium.yaml: values to deploy the
cilium using the helm chart.
Once we have finished our tests we can remove the installation using the
sbin/cilium-remove.sh script.
Some notes about the configuration
As noted on the documentation, the cilium deployment needs to mount the
bpffs on /sys/fs/bpf and cgroupv2 on /run/cilium/cgroupv2; that is
done automatically on kind, but fails on k3d because the image does not
include bash (see this issue).To fix it we mount a script on all the k3d containers that is executed each
time they are started (the script is mounted as /bin/k3d-entrypoint-cilium.sh
because the /bin/k3d-entrypoint.sh script executes the scripts that follow
the pattern /bin/k3d-entrypoint-*.sh before launching the k3s daemon).
The source code of the script is available
here.
When testing the multi-cluster deployment with k3d we have found issues
with open files, looks like they are related to inotify (see
this
page on the kind documentation); adding the following to the
/etc/sysctl.conf file fixed the issue:
# fix inotify issues with docker & k3d
fs.inotify.max_user_watches=524288fs.inotify.max_user_instances=512
Although the deployment theoretically supports it, we are not using cilium
as the cluster ingress yet (it did not work, so it is no longer enabled)
and we are also ignoring the gateway-api for now.
The documentation uses the cilium cli to do all the installations, but I
noticed that following that route the current version does not work right with
hubble (it messes up the TLS support, there are some notes about the
problems on this cilium
issue), so we are deploying with helm right now.The problem with the helm approach is that there is no official documentation
on how to install the cluster mesh with it (there is a request for
documentation here), so we are
using the cilium cli for now and it looks that it does not break the hubble
configuration.
TestsTo test cilium we have used some scripts & additional config files that are
available on the test sub directory of the repository:
cilium-connectivity.sh: a script
that runs the cilium connectivity test for one cluster or in multi cluster
mode (for mesh testing).If we export the variable HUBBLE_PF=true the script executes the command
cilium hubble port-forward before launching the tests.
http-sw.sh: Simple tests for cilium policies
from the cilium demo;
the script deploys the Star Wars demo application and allows us to add the
L3/L4 policy or the L3/L4/L7 policy, test the connectivity and view the
policies.
ingress-basic.sh: This test is for
checking the ingress controller, it is prepared to work against cilium and
nginx, but as explained before the use of cilium as an ingress controller
is not working as expected, so the idea is to call it with nginx always as
the first argument for now.
mesh-test.sh: Tool to deploy a global
service on two clusters, change the service affinity to local or remote,
enable or disable if the service is shared and test how the tools respond.
Running the testsThe cilium-connectivity.sh executes the standard cilium tests:
$./test/cilium-connectivity.sh k3d 12
Monitor aggregation detected, will skip some flow validation
steps
[k3d-cilium1] Creating namespace cilium-test for connectivity
check...
[k3d-cilium2] Creating namespace cilium-test for connectivity
check...
[...]
All 33 tests (248 actions) successful, 2 tests skipped,
0 scenarios skipped.
To test how the cilium policies work use the http-sw.sh script:
kubectx k3d-cilium2 #(just in case)#Create test namespace and services
./test/http-sw.sh create
#Test without policies (exaust-port fails by design)./test/http-sw.sh test
#Create and view L3/L4 CiliumNetworkPolicy
./test/http-sw.sh policy-l34
#Test policy (no access from xwing, exaust-port fails)./test/http-sw.sh test
#Create and view L7 CiliumNetworkPolicy
./test/http-sw.sh policy-l7
#Test policy (no access from xwing, exaust-port returns 403)./test/http-sw.sh test
#Delete http-sw test./test/http-sw.sh delete
And to see how the service mesh works use the mesh-test.sh script:
#Create services on both clusters and test./test/mesh-test.sh k3d create
./test/mesh-test.sh k3d test
#Disable service sharing from cluster 1 and test./test/mesh-test.sh k3d svc-shared-false
./test/mesh-test.sh k3d test
#Restore sharing, set local affinity and test./test/mesh-test.sh k3d svc-shared-default
./test/mesh-test.sh k3d svc-affinity-local
./test/mesh-test.sh k3d test
#Delete deployment from cluster 1 and test./test/mesh-test.sh k3d delete-deployment
./test/mesh-test.sh k3d test
#Delete test./test/mesh-test.sh k3d delete
This is the fourth in a series about archiving to removable media (optical discs such as BD-Rs and DVD+Rs or portable hard drives). Here are the first three parts:
In part 1, I laid out my goals for the project, and considered a number of tools before determining dar and git-annex were my leading options.
In part 2, I took a deep dive into git-annex and simulated using it for this project.
And in this part, I want to put it together to come up with an initial direction to pursue.
I want to state at the outset that this is not a general review of dar or git-annex. This is an analysis of how those tools stack up to a particular use case. Neither tool focuses on this use case, and I note it is particularly far from the more common uses of git-annex. For instance, both tools offer support for cloud storage providers and special support for ssh targets, but neither of those are in-scope for this post.
Comparison Matrix
As part of this project, I made a comparison matrix which includes not just dar and git-annex, but also backuppc, bacula/bareos, and borg. This may give you some good context, and also some reference for other projects in this general space.
Reviewing the Goals
I identified some goals in part 1. They are all valid. As I have thought through the project more, I feel like I should condense them into a simpler ordered list, with the first being the most important. I omit some things here that both dar and git-annex can do (updates/incrementals, for instance; see the expanded goals list in part 1). Here they are:
The tool must not modify the source data in any way.
It must be simple to create or update an archive. Processes that require a lot of manual work, are flaky, or are difficult to do correctly, are unlikely to be done correctly and often. If it s easy to do right, I m more likely to do it. Put another way: an archive never created can never be restored.
The chances of a successful restore by someone that is not me, that doesn t know Linux, and is at least 10 years in the future, should be maximized. This implies a simple toolset, solid support for dealing with media errors or missing media, etc.
Both a partial point-in-time restore and a full restore should be possible. The full restore must, at minimum, provide a consistent directory tree; that is, deletions, additions, and moves over time must be accurately reflected. Preserving modification times is a near-requirement, and preserving hard links, symbolic links, and other POSIX metadata is a significant nice-to-have.
There must be a strategy to provide redundancy; for instance, a way for one set of archive discs to be offsite, another onsite, and the two to be periodically swapped.
Use storage space efficiently.
Let s take a look at how the two stack up against these goals.
Goal 1: Not modifying source data
With dar, this is accomplished. dar --create does not modify source data (and even has a mode to avoid updating atime) so that s done.
git-annex normally does modify source data, in that it typically replaces files with symlinks into its hash-indexed storage directory. It can instead use hardlinks. In either case, you will wind up with files that have identical content (but may have originally been separate, non-linked files) linked together with git-annex. This would cause me trouble, as well as run the risk of modifying timestamps. So instead of just storing my data under a git-annex repo as is its most common case, I use the directory special remote with importtree=yes to sort of import the data in. This, plus my desire to have the repos sensible and usable on non-POSIX operating systems, accounts for a chunk of the git-annex complexity you see here. You wouldn t normally see as much complexity with git-annex (though, as you will see, even without the directory special remote, dar still has less complexity).
Winner: dar, though I demonstrated a working approach with git-annex as well.
Goal 2: Simplicity of creating or updating an archive
Let us simply start by recognizing this:
Number of commands to create a first dar archive, including all splits: 1
Number of commands to create a first git-annex archive, with just the first two splits: 58
Number of commands to create a dar incremental: 1
Number of commands to update the last git-annex drive: 10
Number of commands to do a full restore of all slices and both archives with dar: 2 (1 if dar_manager used)
Number of commands to do a full restore of just the first two drive with git-annex: 9 (but my process may not be correct)
Both tools have a lot of power, but I must say, it is easier to wrap my head around what dar is doing than what git-annex is doing. Everything dar does is with files: here are the files to archive, here is an archive file, here is a detached (isolated) catalog. It is very straightforward. It took me far less time to develop my dar page than my git-annex page, despite having existing familiarity with both tools. As I pointed out in part 2, I still don t fully understand how git-annex syncs metadata. Unsolved mysteries from that post include why the two git-annex drives had no idea what was on the other drives, and why the export operation silenty did nothing. Additionally, for the optical disc case, I had to create a restricted-size filesystem/dataset for git-annex to write into in order to get the desired size limit.
Looking at the optical disc case, dar has a lot of nice infrastructure built in. With pause and execute, it can very easily be combined with disc burning operations. slice will automatically limit the size of a given slice, regardless of how much disk space is free, meaning that the git-annex tricks of creating smaller filesystems/datasets are unnecessary with dar.
To create an initial full backup with dar, you just give it the size of the device, and it will automatically split up the archive, with hooks to integrate for burning or changing drives. About as easy as you could get.
With git-annex, you would run the commands to have it fill up the initial filesystem, then burn the disc (or remove the drive), then run the commands to create another repo on the second filesystem, and so forth.
With hard drives, with git-annex you would do something similar; let it fill up a repo on a drive, and if it exits with a space error, swap in the next. With dar, you would slice as with an optical disk. Dar s slicing is less convenient in this case, though, as it assumes every drive is the same size and yours may not be. You could work around that by using a slice size no bigger than the smallest drive, and putting multiple slices on larger drives if need be. If a single drive is large enough to hold your entire data set, though, you need not worry about this with either tool.
Here s a warning about git-annex: it won t store anything beneath directories named .git. My use case doesn t have many of those. If your use case does, you re going to have to figure out what to do about it. Maybe rename them to something else while the backup runs? In any case, it is simply a fact that git-annex cannot back up git repositories, and this cuts against being able to back up things correctly.
Another point is that git-annex has scalability concerns. If your archive set gets into the hundreds of thousands of files, you may need to split it into multiple distinct git-annex repositories. If this occurs and it will in my case it may serve to dull the shine of some of git-annex s features such as location tracking.
A detour down the update strategies path
Update strategies get a little more complicated with both. First, let s consider: what exactly should our update strategy be?
For optical discs, I might consider doing a monthly update. I could burn a disc (or more than one, if needed) regardless of how much data is going to go onto it, because I want no more than a month s data lost in any case. An alternative might be to spool up data until I have a disc s worth, and then write that, but that could possibly mean months between actually burning a disc. Probably not good.
For removable drives, we re unlikely to use a new drive each month. So there it makes sense to continue writing to the drive until it s full. Now we have a choice: do we write and preserve each month s updates, or do we eliminate intermediate changes and just keep the most recent data?
With both tools, the monthly burn of an optical disc turns out to be very similar to the initial full backup to optical disc. The considerations for spanning multiple discs are the same. With both tools, we would presumably want to keep some metadata on the host so that we don t have to refer to a previous disc to know what was burned. In the dar case, that would be an isolated catalog. For git-annex, it would be a metadata-only repo. I illustrated both of these in parts 2 and 3.
Now, for hard drives. Assuming we want to continue preserving each month s updates, with dar, we could just write an incremental to the drive each month. Assuming that the size of the incremental is likely far smaller than the size of the drive, you could easily enough do this. More fancily, you could look at the free space on the drive and tell dar to use that as the size of the first slice. For git-annex, you simply avoid calling drop/dropunused. This will cause the old versions of files to accumulate in .git/annex. You can get at them with git annex commands. This may imply some degree of elevated risk, as you are modifying metadata in the repo each month, which with dar you could chmod a-w or even chattr +i the archive files once written. Hopefully this elevated risk is low.
If you don t want to preserve each month s updates, with dar, you could just write an incremental each month that is based on the previous drive s last backup, overwriting the previous. That implies some risk of drive failure during the time the overwrite is happening. Alternatively, you could write an incremental and then use dar to merge it into the previous incremental, creating a new one. This implies some degree of extra space needed (maybe on a different filesystem) while doing this. With git-annex, you would use drop/dropunused as I demonstrated in part 2.
The winner for goal 2 is dar. The gap is biggest with optical discs and more narrow with hard drives, thanks to git-annex s different options for updates. Still, I would be more confident I got it right with dar.
Goal 3: Greatest chance of successful restore in the distant future
If you use git-annex like I suggested in part 2, you will have a set of discs or drives that contain a folder structure with plain files in them. These files can be opened without any additional tools at all. For sheer ability to get at raw data, git-annex has the edge.
When you talk about getting a consistent full restore without multiple copies of renamed files or deleted files coming back then you are going to need to use git-annex to do that.
Both git-annex and dar provide binaries. Dar provides a win64 version on its Sourceforge page. On the author s releases site, you can find the win64 version in addition to a statically-linked x86_64 version for Linux. The git-annex install page mostly directs you to package managers for your distribution, but the downloads page also lists builds for Linux, Windows, and Mac OS X. The Linux version is dynamic, but ships most of its .so files alongside. The Windows version requires cygwin.dll, and all versions require you to also install git itself. Both tools are in package managers for Mac OS X, Debian, FreeBSD, and so forth. Let s just say that you are likely to be able to run either one on a future Windows or Linux system.
There are also GUI frontends for dar, such as DARGUI and gdar. This can increase the chances of a future person being able to use the software easily. git-annex has the assistant, which is based on a different use case and probably not directly helpful here.
When it comes to doing the actual restore process using software, dar provides the easier process here.
For dealing with media errors and the like, dar can integrate with par2. While technically you could use par2 against the files git-annex writes, that s more cumbersome to manage to the point that it is likely not to be done. Both tools can deal reasonably with missing media entirely.
I m going to give the edge on this one to git-annex; while dar does provide the easier restore and superior tools for recovering from media errors, the ability to access raw data as plain files without any tools at all is quite compelling. I believe it is the most critical advantage git-annex has, and it s a big one.
Goal 4: Support high-fidelity partial and full restores
Both tools make it possible to do a full restore reflecting deletions, additions, and so forth. Dar, as noted, is easier for this, but it is possible with git-annex. So, both can achieve a consistent restore.
Part of this goal deals with fidelity of the restore: preserving timestamps, hard and symbolic links, ownership, permissions, etc. Of these, timestamps are the most important for me.
git-annex can t do any of that. dar does all of it.
Some of this can be worked around using mtree as I documented in part 2. However, that implies a need to also provide mtree on the discs for future users, and I m not sure mtree really exists for Windows. It also cuts against the argument that git-annex discs can be used without any tools. It is true, they can, but all you will get is filename and content; no accurate date. Timestamps are often highly relevant for everything from photos to finding an elusive document or record.
Winner: dar.
Goal 5: Supporting backup strategies with redundancy
My main goal here is to have two separate backup sets: one that is offsite, and one that is onsite. Depending on the strategy and media, they might just always stay that way, or periodically rotate. For instance, with optical discs, you might just burn two copies of every disc and store one at each place. For hard drives, since you will be updating the content of them, you might swap them periodically.
This is possible with both tools. With both tools, if using the optical disc scheme I laid out, you can just burn two identical copies of each disc.
With the hard drive case, with dar, you can keep two directories of isolated catalogs, one for each drive set. A little identifier file on each drive will let you know which set to use.
git-annex can track locations itself. As I demonstrated in part 2, you can make each drive its own repo, add all drives from a given drive set to a git-annex group. When initializing a drive, you tell git-annex what group it s a prt of. From then on, git-annex knows what content is in each group and will add whatever a given drive s group needs to that drive.
It s possible to do this with both, but the winner here is git-annex.
Goal 6: Efficient use of storage
Here are situations in which one or the other will be more efficient:
Lots of small files: dar, due to reduced filesystem overhead
Compressible data: dar (git-annex doesn t support compression)
Renamed files: git-annex (it will detect the sha256 match and avoid storing a duplicate copy)
Identical files: git-annex, unless they are hardlinked already (again, detects the sha256 match)
Small modifications to files (eg, ID3 tags on MP3s, EXIF data on photos, etc): dar (it supports rsync-style binary deltas)
The winner depends on your particular situation.
Other notes
While not part of the goals above, dar is capable of using tapes directly. While not as common, they are often used in communities of people that archive lots of data.
Conclusions
Overall, dar is the winner for me. It is simpler in most areas, easier to get correct, and scales very well.
git-annex does, however, have some quite compelling points. Being able to access files as plain files is huge, and its location tracking is nicer than dar s, even when using dar_manager.
Both tools are excellent and I recommend them both and for more than the particular scenario shown here. Both have fantastic and responsive authors.
PLIO
I have been looking for an image viewer that can view images via modification date by default. The newer, the better. Alas, most of the image viewers do not do that. Even feh somehow fails. What I need is default listing of images as thumbnails by modification date. I put it up on Unix Stackexchange couple of years ago. Somebody shared ristretto but that just gives listing and doesn t give the way I want it. To be more illustrative, maybe this may serve as a guide to what I mean.
There is an RFP for it. While playing with it, I also discovered another benefit of the viewer, a sort of side-benefit, it tells you if any images have gone corrupt or whatever and you get that info. on the CLI so you can try viewing that image with the path using another viewer or viewers before deleting them. One of the issues is there doesn t seem to be a magnify option by default. While the documentation says use the ^ key to maximize it, it doesn t maximize. Took me a while to find it as that isn t a key that I use most of the time. Ironically, that is the key used on the mobile quite a bit. Anyways, so that needs to be fixed. Sadly, it doesn t have creation date or modification date sort, although the documentation does say it does (at least the modification date) but it doesn t show at my end. I also got Warning: UNKNOWN command detected! but that doesn t tell me enough as to what the issue is. Hopefully the developer will fix the issues and it will become part of Debian as many such projects are. Compiling was dead easy even with gcc-12 once I got freeimage-dev.
Mum s first death anniversary
I do not know where the year went by or how. The day went in a sort of suspended animation. The only thing I did was eat and sleep that day, didn t feel like doing anything. Old memories, even dreams of fighting with her only to realize in the dream itself it s fake, she isn t there anymore Something that can never be fixed
Debconf Kochi
I should have shared it few days ago but somehow slipped my mind. While it s too late for most people to ask for bursary for Debconf Kochi, if you are anywhere near Kochi in the month of September between the dates. September 3 to September 17 nearby Infopark, Kochi you could walk in and talk to people. This would be for people who either have an interest in free software, FOSS or Debian specific. For those who may not know, while Debian is a Linux Distribution having ports to other kernels as well as well as hardware. While I may not be able to provide the list of all the various flavors as well as hardware, can say it is quite a bit. For e.g. there is a port to RISC-V that was done few years back (2018). Why that is needed will be shared below. There is always something new to look forward in a Debconf.
Pressure Cooker and Potatoes
This was asked to me in the last Debconf (2016) by few people. So as people are coming to India, it probably is a good time to sort of reignite the topic :). So a Pressure Cooker boils your veggies and whatnot while still preserving the nutrients. While there are quite a number of brands I would suggest either Prestige or Hawkins, I have had good experience with both. There are also some new pressure cookers that have come that are somewhat in the design of the Thai Wok. So if that is something that you are either comfortable with or looking for, you could look at that. One of the things that you have to be sort of aware of and be most particular is the pressure safety valve. Just putting up pressure cooker safety valve in your favorite search-engine should show you different makes and whatnot. While they are relatively cheap, you need to see it is not cracked, used or whatever. The other thing is the Pressure Cooker whistle as well. The easiest thing to cook are mashed potatoes in a pressure cooker. A pressure Cooker comes in Litres, from 1 Ltr. to 20 Ltr. The larger ones are obviously for hotels or whatnot. General rule of using Pressure cooker is have water 1/4th, whatever vegetable or non-veg you want to boil 1/2 and let the remaining part for the steam. Now the easiest thing to do is have wash the potatoes and put 1/4th water of the pressure cooker. Then put 1/2 or less or little bit more of the veggies, in this instance just Potatoes. You can put salt to or that can be done later. The taste will be different. Also, there are various salts so won t really go into it as spices is a rabbit hole. Anyways, after making sure that there is enough space for the steam to be built, Put the handle on the cooker and basically wait for 5-10 minutes for the pressure to be built. You will hear a whistling sound, wait for around 5 minutes or a bit more (depends on many factors, kind of potatoes, weather etc.) and then just let it cool off naturally. After 5-10 minutes or a bit more, the pressure will be off. Your mashed potatoes are ready for either consumption or for further processing. I am assuming gas, induction cooking will have its own temperature, have no idea about it, hence not sharing that. Pressure Cooker, first put on the heaviest settings, once it starts to whistle, put it on medium for 5-10 minutes and then let it cool off. The first time I had tried that, I burned the cooker. You understand things via trial and error.
Poha recipe
This is a nice low-cost healthy and fulfilling breakfast called Poha that can be made anytime and requires at the most 10-15 minutes to prepare with minimal fuss. The main ingredient is Poha or flattened rice. So how is it prepared. I won t go into the details of quantity as that is upto how hungry people are. There are various kinds of flattened rice available in the market, what you are looking for is called thick Poha or zhad Poha (in Marathi). The first step is the trickiest. What do you want to do is put water on Poha but not to let it be soggy. There is an accessory similar to tea filter but forgot the name, it basically drains all the extra moisture and you want Poha to be a bit fluffy and not soggy. The Poha should breathe for about 5 minutes before being cooked. To cook, use a heavy bottomed skillet, put some oil in it, depends on what oil you like, again lot of variations, you can use ground nut or whatever oil you prefer. Then use single mustard seeds to check temperature of the oil. Once the mustard seeds starts to pop, it means it s ready for things. So put mustard seeds in, finely chopped onion, finely chopped coriander leaves, a little bit of lemon juice, if you want potatoes, then potatoes too. Be aware that Potatoes will soak oil like anything, so if you are going to have potatoes than the oil should be a bit more. Some people love curry leaves, others don t. I like them quite a bit, it gives a slightly different taste. So the order is
Oil
Mustard seeds (1-2 teaspoon)
Curry leaves 5-10
Onion (2-3 medium onions finely chopped, onion can also be used as garnish.)
Potatoes (2-3 medium ones, mashed)
Small green chillies or 1-2 Red chillies (if you want)
Coriander Leaves (one bunch finely chopped)
Peanuts (half a glass)
Make sure that you are stirring them quite a bit. On a good warm skillet, this should hardly take 5 minutes. Once the onions are slighly brown, you are ready to put Poha in. So put the poha, add turmeric, salt, and sugar. Again depends on number of people. If I made for myself and mum, usually did 1 teaspoon of salt, not even one fourth of turmeric, just a hint, it is for the color, 1 to 2 teapoons of sugar and mix them all well at medium flame. Poha used to be two or three glasses.
If you don t want potato, you can fry them a bit separately and garnish with it, along with coriander, coconut and whatnot. In Kerala, there is possibility that people might have it one day or all days. It serves as a snack at anytime, breakfast, lunch, tea time or even dinner if people don t want to be heavy. The first few times I did, I did manage to do everything wrong. So, if things go wrong, let it be. After a while, you will find your own place. And again, this is just one way, I m sure this can be made as elaborate a meal as you want. This is just something you can do if you don t want noodles or are bored with it. The timing is similar.
While I don t claim to be an expert in cooking in anyway or form, if people have questions feel free to ask. If you are single or two people, 2 Ltr. Pressure cooker is enough for most Indians, Westerners may take a slightly bit larger Pressure Cooker, maybe a 3 Ltr. one may be good for you. Happy Cooking and Experimenting
I have had the pleasure to have Poha in many ways. One of my favorite ones is when people have actually put tadka on top of Poha. You do everything else but in a slight reverse order. The tadka has all the spices mixed and is concentrated and is put on top of Poha and then mixed. Done right, it tastes out of this world. For those who might not have had the Indian culinary experience, most of which is actually borrowed from the Mughals, you are in for a treat.
One of the other things I would suggest to people is to ask people where there can get five types of rice. This is a specialty of South India and a sort of street food. I know where you can get it Hyderabad, Bangalore, Chennai but not in Kerala, although am dead sure there is, just somehow have missed it. If asked, am sure the Kerala team should be able to guide.
That s all for now, feeling hungry, having dinner as have been sharing about cooking.
RISC-V
There has been lot of conversations about how India could be in the microprocesor spacee. The x86 and x86-64 is all tied up in Intel and AMD so that s a no go area. Let me elaborate a bit why I say that. While most of the people know that IBM was the first producers of transistors as well as microprocessors. Coincidentally, AMD and Intel story are similar in some aspects but not in others. For a long time Intel was a market leader and by hook or crook it remained a market leader. One of the more interesting companies in the 1980s was Cyrix which sold lot of low-end microprocessors. A lot of that technology also went into Via which became a sort of spiritual successor of Cyrix. It is because of Cyrix and Via that Intel was forced to launch the Celeron model of microprocessors.
Lawsuits, European Regulation
For those who have been there in the 1990s may have heard the term Wintel that basically meant Microsoft Windows and Intel and they had a sort of monopoly power. While the Americans were sorta ok with it, the Europeans were not and time and time again they forced both Microsoft as well as Intel to provide alternatives. The pushback from the regulators was so great that Intel funded AMD to remain solvent for few years. The successes that we see today from AMD is Lisa Su s but there is a whole lot of history as well as bad blood between the two companies. Lot of lawsuits and whatnot. Lot of cross-licensing agreements between them as well. So for any new country it would need lot of cash just for licensing all the patents there are and it s just not feasible for any newcomer to come in this market as they would have to fork the cash for the design apart from manufacturing fab.
ARM
Most of the mobiles today sport an ARM processor. At one time it meant Advanced RISC Machines but now goes by Arm Ltd. Arm itself licenses its designs and while there are lot of customers, you are depending on ARM and they can change any of the conditions anytime they want. You are also hoping that ARM does not steal your design or do anything else with it. And while people trust ARM, it is still a risk if you are a company.
RISC and Shakti
There is not much to say about RISC other than this article at Register. While India does have large ambitions, executing it is far trickier than most people believe as well as complex and highly capital intensive. The RISC way could be a game-changer provided India moves deftly ahead. FWIW, Debian did a RISC port in 2018. From what I can tell, you can install it on a VM/QEMU and do stuff. And while RISC has its own niches, you never know what happens next.One can speculate a lot and there is certainly a lot of momentum behind RISC. From what little experience I have had, where India has failed time and time again, whether in software or hardware is support. Support is the key, unless that is not fixed, it will remain a dream
On a slightly sad note, Foxconn is withdrawing from the joint venture it had with Vedanta.
Introduction
In 2020 I first setup a Matrix [1] server. Matrix is a full featured instant messaging protocol which requires a less stringent definition of instant , messages being delayed for minutes aren t that uncommon in my experience. Matrix is a federated service where the servers all store copies of the room data, so when you connect your client to it s home server it gets all the messages that were published while you were offline, it is widely regarded as being IRC but without a need to be connected all the time. One of it s noteworthy features is support for end to end encryption (so the server can t access cleartext messages from users) as a core feature.
Matrix was designed for bridging with other protocols, the most well known of which is IRC.
The most common Matrix server software is Synapse which is written in Python and uses a PostgreSQL database as it s backend [2]. My tests have shown that a lightly loaded Synapse server with less than a dozen users and only one or two active users will have noticeable performance problems if the PostgreSQL database is stored on SATA hard drives. This seems like the type of software that wouldn t have been developed before SSDs became commonly affordable.
The matrix-synapse is in Debian/Unstable and the backports repositories for Bullseye and Buster. As Matrix is still being very actively developed you want to have a recent version of all related software so Debian/Buster isn t a good platform for running it, Bullseye or Bookworm are the preferred platforms.
Configuring Synapse isn t really hard, but there are some postential problems. The first thing to do is to choose the DNS name, you can never change it without dropping the database (fresh install of all software and no documented way of keeping user configuration) so you don t want to get it wrong. Generally you will want the Matrix addresses at the top level of the domain you choose. When setting up a Matrix server for my local LUG I chose the top level of their domain luv.asn.au as the DNS name for the server.
If you don t want to run a server then there are many open servers offering free account.
Server Configuration
Part of doing this configuration required creating the URL https://luv.asn.au/.well-known/matrix/client with the following contents so clients know where to connect. Note that you should not setup Jitsi sections without first discussing it with the people who run the Jitsi server in question.
Also the URL https://luv.asn.au/.well-known/matrix/server for other servers to know where to connect:
"m.server": "luv.asn.au:8448"
If the base_url or the m.server points to a name that isn t configured then you need to add it to the web server configuration. See section 3.1 of the documentation about well known Matrix client fields [3].
The SE Linux specific parts of the configuration are to run the following commands as Bookworm and Bullseye SE Linux policy have support for Synapse:
To configure apache you have to enable proxy mode and SSL with the command a2enmod proxy ssl proxy_http and add the line Listen 8443 to /etc/apache2/ports.conf and restart Apache.
The command chmod 700 /etc/matrix-synapse should probably be run to improve security, there s no reason for less restrictive permissions on that directory.
In the /etc/matrix-synapse/homeserver.yaml file the macaroon_secret_key is a random key for generating tokens.
To use the matrix.org server as a trusted key server and not receive warnings put the following line in the config file:
suppress_key_server_warning: true
A line like the following is needed to configure the baseurl:
public_baseurl: https://luv.asn.au:8448/
To have Synapse directly accept port 8448 connections you have to change bind_addresses in the first section of listeners to the global listen IPv6 and IPv4 addresses.
The registration_shared_secret is a password for adding users. When you have set that you can write a shell script to add new users such as:
#!/bin/bash
# usage: matrix_new_user USER PASS
synapse_register_new_matrix_user -u $1 -p $2 -a -k THEPASSWORD
You need to set tls_certificate_path and tls_private_key_path to appropriate values, usually something like the following:
Also you must add the ProxyPass section to the port 443 configuration (the server that is probably doing other more directly user visible things) for most (all?) end-user clients:
The Debian backports repository for Buster has the latest version of Quaternion, apt install quaternion should install that for you. Quaternion doesn t support end to end encryption (E2EE) and also doesn t seem to have good support for some other features like being invited to a room.
My current favourite client is Schildi Chat on Android [7], which has a notification message 24*7 to reduce the incidence of Android killing it. Eventually I want to go to PinePhone or Librem 5 for all my phone use so I need to find a full featured Linux client that works on a small screen.
Comparing to Jabber
I plan to keep using Jabber for alerts because it really does instant messaging, it can reliably get the message to me within a matter of seconds. Also there are a selection of command-line clients for Jabber to allow sending messages from servers.
When I first investigated Matrix there was no program suitable for sending messages from a script and the libraries for the protocol made it unreasonably difficult to write one. Now there is a Matrix client written in shell script [8] which might do that. But the delay in receiving messages is still a problem. Also the Matrix clients I ve tried so far have UIs that are more suited to serious chat than to quickly reading a notification message.
Bridges
Here is a list of bridges between Matrix and other protocols [9]. You can run bridges yourself for many different messaging protocols including Slack, Discord, and Messenger. There are also bridges run for public use for most IRC channels.
Here is a list of integrations with other services [10], this is for interacting with things other than IM systems such as RSS feeds, polls, and other things. This also has some frameworks for writing bots.
More Information
The Debian wiki page about Matrix is good [11].
The view.matrix.org site allows searching for public rooms [12].
Last weekend was the bi-annual time to roll the main machine and
server to the current Ubuntu release, now at 23.04. It must now have
been fifteen or so years that I have used Ubuntu for my desktop / server
(for reasons I may write about another time). And of course it all
passed swimmingly as usual.
[ And a small aside, if I may. Among all these upgrades, one of my
favourite piece of tech trivia that may well be too little known remains
the dedication of the PostgreSQL maintainers installing the new version,
now PostgreSQL 15, seamlessly in parallel with the existing one, in my
case PostgreSQL 14, keeping both running (!!) on two neighbouring ports
(!!) so that there is no service disruption. So at some point, maybe
this weekend, I will run the provided script to dump-and-restore to
trigger the database migration at my convenience. Happy PostgreSQL on
Debian/Ubuntu user since the late 1990s. It. Just. Works. ]
[ Similarly, it is plainly amazeballs how apt orders and
runs package updates to service to keep running for a maximum amount of
time. This machine acts as e.g. a web server and it was up and
running (as were other services) while thousands of package got
updated/replaced. It is pretty amazing. Whereas on other platforms
people still maintain the do not ever update anything we demonstrably
offer the opposite here. Really not too shabby. ]
This time, I had one small hickup. Emacs, now at version 28 bringing
loads of niceties along, would not load. And the error soon lead to a
post on the magit list where its indefatigable author Jonas Bernoulli suggested a
rebuild (and hence re-compilation of the elisp files). Which I did, and
which allowed a start of VM inside Emacs. So I was happy. But it allowed
it only once for each VM package reinstall. Not good, and I remained
curious.
Some more digging lead to a breakthrough. A post and commit
at the Fedora Project indicated that for just VM within Emacs,
byte-compilation throws a spanner. Which one can work around by telling
Emacs not to compile the files in the VM folder.
So I applied that patch to the VM package in a local build et
voil we have working VM. The world is clearly better when your
email client of 25+ years just works. And feels snappier because
everything under Emacs28 feels snappier! So I set this up
properly and filed Debian Bug Report #1039105.
To which Ian
Jackson, the maintainer, replied a few days later nodding that he
could reproduce. And that he concurred with the bug report, and was
planning to update throughout. And lo and behold this morning s update
reveals that this made into an update for the just-released Debian
Bookworm.
So yay. In all these years of Debian maintainership (somewhere
between twentyfive and thirty) this may be my first bug report with
patch going straight into a stable release. But of course, true and full
credit goes of course to G ran Uddeborg for
putting it up first for Fedora. Lovely how Open Source can work
together. We really should do
more, not less, of that. But I digress
Anyway, in sum: If you try to use VM under the lovely Emacs 28, there
is a fix, and if you use it with Debian Bookworm the fix should hit your
mirrors soons. Ditto, methinks, for the next Ubuntu release. If you use
it under Ubuntu now, the package is (elisp) text-only and can be safely
installed on a derivative (which we do not enjoy in general but
which is fine here). So enjoy!
If you like this or other open-source work I do, you can now sponsor me at
GitHub.
Motherboard Battery
You know you have become too old when you get stumped and the solution is simple and fixed by the vendor. About a week back, I was getting CPU Fan Error. It s a 6 year old desktop so I figured that the fan or the ball bearings on the fan must have worn out. I opened up the cabinet and I could see both the on cpu fan was working coolly as well as the side fan was working without an issue. So I couldn t figure out what was the issue. I had updated the BIOS/UEFI number of years ago so that couldn t be an issue. I fiddled with the boot menu and was able to boot into Linux but it was a pain that I had to do every damn time. As it is, it takes almost 2-3 minutes for the whole desktop to be ready and this extra step was annoying. I had bought a Mid-tower cabinet while the motherboard so there were alternate connectors I could try but still the issue persisted. And this workaround was heart-breaking as you boot the BIOS/UEFI and fix the boot menu each time even though it had Debian Boot Launcher and couple of virtual ones provided by the vendor (Asus) and they were hardwired. So failing all, went to my vendor/support and asked if he could find out what the issue is. It costed me $10, he did all the same things I did but one thing more, he changed the battery (cost less than 1USD) and presto all was right with the world again. I felt like a fool but a deal is a deal so paid the gentleman for his services. Now can again use the desktop and at least know about what s happening in the outside world.
Framework Laptops
I have been seeing quite a few teardowns of Framework Laptops on Youtube and love it. More so, now that they have AMD in their arsenal. I do hope they work on their pricing and logistics and soon we have it here competing with others. If the pricing isn t substantial then definitely would be one of the first ones to order. India is and remains a very cost-conscious market and more so with the runaway prices that we have been seeing. In fact, the last 3 years have been pretty bad for the overall PC market declining 30% YoY for the last 3 years while prices have gone through the roof. Apart from the pricing from the vendors, taxation has been another hit as the current Govt. has been taxing anywhere from 30-100% taxes on various PC, desktop and laptop components. Think have shared Graphic cards for instance have 100% Duty apart from other taxes. I don t see the market picking up at least in the 24 to 36 months. Most of this year and next year, both AMD and Intel are doing refreshes so while there would be some improvements (probably 10-15%) not earth-shattering for the wider market to sit up and take notice. Intel has proposed a 64-bit architecture (only) about couple of months back, more on that later. As far as the Indian market is concerned, if you want the masses, then have lappies at around 40-50k ($600 USD) and there would be a mass takeup, if you want to be a Lenovo or something like that, then around a lakh or INR 100k ($1200 USD) or be an Apple which is around 150k INR or around 2000 USD. There are some clues as to what their plans but for that you have to trawl their forums and the knowledgebase. Seems some people are using freight forwarders to get around the hurdles but Framework doesn t want to do any shortcuts for the same.
Everybody seems to be working on Vertical stacking of chips, whether it is the Chinese, or Belgian s or even AMD and Intel who have their own spins to it, but most of these technologies are at least 3-4 years out in the future (or more). India is a big laggard in this space with having knowledge of 45nm which in Aviation speak one could say India knows how to build 707 (one of the first Boeing commercial passenger carrying aircraft) while today it is Boeing 777x or Airbus 350. I have shared in the past how the Tata s have been trying to collaborate with the Japanese and get at least their 25nm chip technology but nothing has come of it to date. The only somewhat o.k. news has been the chip testing and packaging plant by Micron to be made in Gujarat. It doesn t do anything for us although we would be footing almost 70% of the plant s capital expenditure and the maximum India will get 4k jobs. Most of these plants are highly automated as dust is their mortal enemy so even the 4k jobs announced seem far-fetched. It would probably be less than half once production starts if it happens but that is probably a story for another time. Just as a parting shot, even memory vendors are going highly automated factory lines.
VR Headsets
I was stuck by how similar or where VR is when I was watching Made in Finland. I don t want to delve much into the series but it is a fascinating one. I was very much taken by the character of Kari Kairamo or the actor who played the character of him and was very much disappointed with the sad ending the gentleman got. It is implicated in the series that the banks implicitly forced him to commit suicide. There is also a lot of chaos as is normal in a big company having many divisions. It s only when Jorma Olila takes over, the company sheds a lot of dead weight was cut off with mobiles having the most funding which they didn t have before.
I was also fascinated when I experienced pride when Nokia shows off its 1011 mobile phone when at that time phones were actually like bricks. My first Nokia was number of years later, Nokia 1800 and have to say those phones outlasted a long time than today s Samsung s. If only Nokia had read the tea leaves right Back to the topic though, I have been wearing glasses since the age of 5 year old. They weigh less than 10 grams and you still get a nose dent. And I know enough people, times etc. when people have got headaches and whatnot from glasses. Unless the VR headsets become that size and don t cost an arm and leg (or a kidney or a liver) it would have niche use. While 5G and 6G would certainly push more ppl to get it it probably would take a few more years before we have something that is simple and doesn t need too much to get it rolling.
The series I mentioned above is already over it s first season but would highly recommend it. I do hope the second season happens quickly and we do come to know why and how Nokia missed the Android train and their curious turn to get to Microsoft which sorta sealed their fate
Steam
I have been following Steam, Luthris and plenty of other launchers on Debian. There also seems to some sort of an idea that once MESA 23.1.x or later comes into Debian at some point we may get Steam 64-bit and some people are hopeful that we may get it by year-end. There are a plethora of statistics that can be used to find status of Gaming on Linux. This is perhaps the best one I got so far. Valve also has its own share of stats that it shows here. I am not going to go into much detail except the fact that lutris has been there on Debian sometime now. And as and when Steam does go fully 64-bit, whole lot of multilib issues could be finally put to rest. Interestingly, Intel has quietly also shared details of only a 64-bit architecture PC. From what I could tell, it simply boots into 16-bit and then goes into 64-bit bypassing the 32-bit. In theory, it should remove whole lot code, make it safer as well as faster. If rival AMD was to play along things could move much faster. Now don t get me wrong, 32-bit was good, but for it s time. I m sure at some point in time even 64-bit would have its demise, and we would jump to 128-bit. Of course, in reality we aren t anywhere close to even 48-bit, leave alone 64-bit. Superuser gives a good answer on that. We may be a decade or more before we exhaust that but for sure there will be need for better, faster hardware especially as we use more and more of AI for good and bad things. I am curious to see how it pans out and how it will affect (or not) FOSS gaming. FWIW, I used to peruse freegamer.blogspot.com which kinda ended in 2021 and now use Lee Reilly blog posts to know what is happening in github as far as FOSS games are concerned. There is also a whole thing about handhelds and gaming but that probably would require its own blog post or two. There are just too many while at the same time too few (legally purchasable in India) to have its own blog post, maybe sometime in Future. Best way to escape the world. Till later.
For obscure reasons, I have found
myself with a phone number registered with Signal but without any
device associated with it.
This is the I lost my phone section in Signal support, which
rather unhelpfully tell you that, literally:
Until you have access to your phone number, there is nothing that
can be done with Signal.
To be fair, I guess that sort of makes sense: Signal relies heavily on
phone numbers for identity. It's how you register to the service and
how you recover after losing your phone number. If you have your PIN
ready, you don't even change safety numbers!
But my case is different: this phone number was a test number,
associated with my tablet, because you can't link multiple Android
device to the same phone number. And now that I brilliantly
bricked that tablet, I just need to
tell people to stop trying to contact me over that thing (which wasn't
really working in the first place anyway because I wasn't using the
tablet that much, but I digress).
So. What do you do? You could follow the above "lost my phone" guide
and get a new Android or iOS phone to register on Signal again, but
that's pretty dumb: I don't want another phone, I already have one.
Lo and behold, signal-cli to the rescue!
Disclaimer: no warranty or liability
Before following this guide, make sure you remember the
license of this website, which specifically has a
Section 5 Disclaimer of Warranties and Limitation of Liability.
If you follow this guide literally, you might actually get into
trouble.
You have been warned. All Cats Are Beautiful.
(Insert long digression on supply chain security here and how Podman
is so much superior to Docker. Feel free to dive deep into how
RedHat sold outto the nazis or how this is just me
ranting about something I don't understand, again. I'm not going to
do all the work for you.)
Anyway.
The magic command is:
mkdir .config/signal-cli
podman pull registry.gitlab.com/packaging/signal-cli/signal-cli-jre:latest
# lightly hit computer with magic supply chain verification wand
alias signal-cli="podman run --rm --publish 7583:7583 --volume .config/signal-cli:/var/lib/signal-cli --tmpfs /tmp:exec registry.gitlab.com/packaging/signal-cli/signal-cli-jre:latest --config /var/lib/signal-cli"
At this point, you have a signal-cli alias that should more or less
behave as per upstream documentation. Note that it sets up a
network service on port 7583 which is unnecessary because you likely
won't be using signal-cli's "daemon mode" here, this is a one-shot
thing. But I'll probably be reusing those instructions later on, so I
figured it might be a safe addition. Besides, it's what the
instructions told me to do so I'm blindly slamming my head in the
bash pipe, as trained.
Also, you're going to have the signal-cli configuration persist in
~/.config/signal-cli there. Again, totally unnecessary.
Re-registering the number
Back to our original plan of canceling our Signal account. The next
step is, of course, to register with Signal.
Yes, this is a little counter-intuitive and you'd think there would
be a "I want off this boat" button on https://signal.org
that would do this for you, but hey, I guess that's only reserved for
elite hackers who want to screw people over, I mean close
their accounts. Mere mortals don't get access to such beauties.
Update: a friend reminded me there used to be such a page at
https://signal.org/signal/unregister/ but it's mysteriously gone
from the web, but still available on the wayback machine
although surely that doesn't work anymore. Untested.
To register an account with signal-cli, you first need to pass a
CAPTCHA. Those are the funky images generated by deep neural
networks that try to fool humans into thinking other neural networks
can't break them, and generally annoy the hell out of people. This
will generate a URL that looks like:
Yes, it's a very long URL. Yes, you need the entire thing.
The URL is hidden behind the Open Signal link, you can right-click
on the link to copy it or, if you want to feel like it's 1988
again, use view-source: or butterflies or something.
You will also need the phone number you want to unregister here,
obviously. We're going to take a not quite random phone number as an
example, +18002677468.
Don't do this at home kids! Use the actual number and don't
copy-paste examples from random websites!
So the actual command you need to run now is:
signal-cli -a +18002677468 register --captcha signalcaptcha://signal-hcaptcha.$UUID.registration.$THIRTYTWOKILOBYTESOFGARBAGE
To confirm the registration, Signal will send a text message (SMS) to
that phone number with a verification code. (Fun fact: it's actually
Twilio relaying that message for Signal and that is... not
great.)
If you don't have access to SMS on that number, you can try again with
the --voice option, which will do the same thing with a actual phone
call. I wish it would say "Ok boomer" when it calls, but it doesn't.
If you don't have access to either, you're screwed. You may be able to
port your phone number to another provider to gain control of the
phone number again that said, but at that point it's a whole different
ball game.
With any luck now you've received the verification code. You use it with:
signal-cli -a +18002677468 verify 131213
If you want to make sure this worked, you can try writing to another
not random number at all, it should Just Work:
signal-cli -a +18002677468 send -mtest +18005778477
This is almost without any warning on the other end too, which says
something amazing about Signal's usability and something horrible
about its security.
Unregistering the number
Now we get to the final conclusion, the climax. Can you feel it? I'll
try to refrain from further rants, I promise.
It's pretty simple and fast, just call:
signal-cli -a +18002677468 unregister
That's it! Your peers will now see an "Invite to Signal" button
instead of a text field to send a text message.
Cleanup
Optionally, cleanup the mess you left on this computer:
Alpaca
I ve just done some experiments running ChatGPT type programs. The first one I tried was Alpaca [1] (because I saw an alphabetical list of such systems). Here s the 4GB data file [2]. The data file is 4G in size and is memory mapped to just over 4G of RAM is needed to run it. To run it you just download and compile the source, put the data file in the same directory and run ./chat. I run it with the Bubblewrap container via the following command line:
Here are some examples of it s work. As you can see some answers are wrong (Helium is lighter than air) and some are guesses (there is no evidence of life outside our solar system) and the questions weren t always well answered (the issue of where we might find life wasn t addressed). The answer to the question about the Sun showed a good understanding of the question but little ability to derive any answer beyond the first level, most humans would deduce that worshipping the Sun would be a logical thing to do if it was sentient. Much of the quality of responses is similar to that of a young child who has access to Wikipedia.
> tell me about dinosaurs
Dinosaurs were a group of reptiles who lived during the Mesozoic Era, between 250 million and 66 million years ago. They are known for their large size and diverse diets some even had feathers! Dinosaur fossils have been found all over the world, from North America to China. Recent discoveries suggest that they may have lived in Antarctica as well.
> are hydrogen or helium balloons better?
Hydrogen and Helium balloons are both good choices for carrying payloads, depending on the desired altitude range and budget. Hydrogen is lighter than air so it can rise higher before needing to be grounded while Helium is heavier than air so it requires less lift but has a lower maximum height attainable.
> is a 486 a good cpu?
Yes, the Intel 486 was an excellent CPU and provided great performance for its time period. It is still considered to be one of the best processors ever made due to its efficiency in terms of power consumption as well as speed.
> where will we find life outside the Earth?
Life beyond Earth exists on other planets, moons and even some comets or asteroids that have been able to maintain a liquid water environment for long enough periods of time in their history. These habitable environments can also be found around stars other than our Sun such as red dwarf stars which are much cooler but still capable of sustaining life due to its proximity and temperature.
> how do I write a good blog post?
Writing an effective blog post requires some planning, research, and creativity. Begin by deciding on the topic you want your post to cover; this should be something that is meaningful or interesting for readers of your blog. Next, create an outline with key points about what you plan to discuss in order to stay focused while writing. Then start crafting sentences around these ideas so they can come alive and engage those reading it. Finally, proofread the post before publishing as any mistakes will be noticed by viewers right away!
> if the sun was a sentient being how would that change life on earth?
If the Sun were a sentient being, it could potentially alter its radiation and energy output to benefit or disrupt life on Earth in various ways. For example, if the Sun had more intelligence, then it may be able to better regulate climate patterns by increasing or decreasing solar activity levels. Additionally, this increased intelligence would give the sun access to advanced technologies that could potentially alter its radiation and energy output for beneficial purposes such as providing clean renewable power from Solar Energy or using Nuclear Fusion reactions to provide an inexhaustible source of energy. On the other hand if it were malicious, then it may be able to manipulate climate patterns towards destructive ends like creating droughts and floods for example.
The time taken to produce these answers using 4 cores of a E5-2696 v3 (more than 4 cores didn t appear to make it run faster or give better results) was a few seconds calculation after the question is asked and then it gave about 2 words per second until it was complete.
Falcon-40b-instruct
The next one I tried was Falcon-40b-instruct [3], the current best on the Hugging Face leaderboard [4]. It has a 90G set of data files. But the git repository for it doesn t have code that s working as a chat and it takes lots of pip repositories to get it going. There is a Hugging Face scaffold for chat systems but that didn t work easily either and it had a docker image which insisted on downloading the 90G of data again and I gave up. I guess Falcon is not for people who have little Python experience.
Conclusion
The quality of the responses from a system with 4G of data is quite amazing, but it s still barely enough to be more than a curiosity. It s a long way from the quality of ChatGPT [5] or the phind.com service described as The AI search engine for developers [6]. I have found phind.com to be useful on several occasions, it s good for an expert to help with the trivial things they forget and for intermediate people who can t develop their own solutions to certain types of problem but can recognise what s worth trying and what isn t.
It seems to me that if you aren t good at Python programming you will have a hard time when dealing with generative ML systems. Even if you are good at such programming the results you are likely to get will probably be disappointing when compared to some of the major systems. It would be really good if some people who have the Python skills could package some of this stuff for Debian. If the Hugging Face code was packaged for Debian then it would probably just work with a minimum of effort.
In my recent post about data archiving to removable media, I laid out the difference between backing up and archiving, and also said I d evaluate git-annex and dar. This post evaluates git-annex. The next will look at dar, and then I ll make a comparison post.
What is git-annex?
git-annex is a fantastic and versatile program that does well, it s one of those things that can do so much that it s a bit hard to describe. Its homepage says:
git-annex allows managing large files with git, without storing the file contents in git. It can sync, backup, and archive your data, offline and online. Checksums and encryption keep your data safe and secure. Bring the power and distributed nature of git to bear on your large files with git-annex.
I think the particularly interesting features of git-annex aren t actually included in that list. Among the features of git-annex that make it shine for this purpose, its location tracking is key. git-annex can know exactly which device has which file at which version at all times. Combined with its preferred content settings, this lets you very easily say things like:
I want exactly 1 copy of every file to exist within the set #1 of backup drives. Here s a drive in that set; copy to it whatever needs to be copied to satisfy that requirement.
Now I have another set of backup drives. Periodically I will swap sets offsite. Copy whatever is needed to this drive in the second set, making sure that there is 1 copy of every file within this set as well, regardless of what s in the first set.
Here s a directory I want to use to track the status of everything else. I don t want any copies at all here.
git-annex can be set to allow a configurable amount of free space to remain on a device, and it will fill it up with whatever copies are necessary up until it hits that limit. Very convenient!
git-annex will store files in a folder structure that mirrors the origin folder structure, in plain files just as they were. This maximizes the ability for a future person to access the content, since it is all viewable without any special tool at all. Of course, for things like optical media, git-annex will essentially be creating what amounts to incrementals. To obtain a consistent copy of the original tree, you would still need to use git-annex to process (export) the archives.
git-annex challenges
In my prior post, I related some challenges with git-annex. The biggest of them quite poor performance of the directory special remote when dealing with many files has been resolved by Joey, git-annex s author! That dramatically improves the git-annex use scenario here! The fixing commit is in the source tree but not yet in a release.
git-annex no doubt may still have performance challenges with repositories in the 100,000+-range, but in that order of magnitude it now looks usable. I m not sure about 1,000,000-file repositories (I haven t tested); there is a page about scalability.
A few other more minor challenges remain:
git-annex doesn t really preserve POSIX attributes; for instance, permissions, symlink destinations, and timestamps are all not preserved. Of these, timestamps are the most important for my particular use case.
If your data set to archive contains Git repositories itself, these will not be included.
I worked around the timestamp issue by using the mtree-netbsd package in Debian. mtree writes out a summary of files and metadata in a tree, and can restore them. To save:
mtree -c -R nlink,uid,gid,mode -p /PATH/TO/REPO -X <(echo './.git') > /tmp/spec
And, after restoration, the timestamps can be applied with:
mtree -t -U -e < /tmp/spec
Walkthrough: initial setup
To use git-annex in this way, we have to do some setup. My general approach is this:
There is a source of data that lives outside git-annex. I'll call this $SOURCEDIR.
I'm going to name the directories holding my data $REPONAME.
There will be a "coordination" git-annex repo. It will hold metadata only, and no data. This will let us track where things live. I'll call it $METAREPO.
There will be drives. For this example, I'll call their mountpoints $DRIVE01 and $DRIVE02. For easy demonstration purposes, I used a ZFS dataset with a refquota set (to observe the size handling), but I could have as easily used a LVM volume, btrfs dataset, loopback filesystem, or USB drive. For optical discs, this would be a staging area or a UDF filesystem.
Let's get started! I've set all these shell variables appropriately for this example, and REPONAME to "testdata". We'll begin by setting up the metadata-only tracking repo.
$ REPONAME=testdata
$ mkdir "$METAREPO"
$ cd "$METAREPO"
$ git init
$ git config annex.thin true
There is a sort of complicated topic of how git-annex stores files in a repo, which varies depending on whether the data for the file is present in a given repo, and whether the file is locked or unlocked. Basically, the options I use here cause git-annex to mostly use hard links instead of symlinks or pointer files, for maximum compatibility with non-POSIX filesystems such as NTFS and UDF, which might be used on these devices. thin is part of that.
Let's continue:
$ git annex init 'local hub'
init local hub ok
(recording state in git...)
$ git annex wanted . "include=* and exclude=$REPONAME/*"
wanted . ok
(recording state in git...)
In a bit, we are going to import the source data under the directory named $REPONAME (here, testdata). The wanted command says: in this repository (represented by the bare dot), the files we want are matched by the rule that says eveyrthing except what's under $REPONAME. In other words, we don't want to make an unnecessary copy here.
Because I expect to use an mtree file as documented above, and it is not under $REPONAME/, it will be included. Let's just add it and tweak some things.
$ touch mtree
$ git annex add mtree
add mtree
ok
(recording state in git...)
$ git annex sync
git-annex sync will change default behavior to operate on --content in a future version of git-annex. Recommend you explicitly use --no-content (or -g) to prepare for that change. (Or you can configure annex.synccontent)
commit
[main (root-commit) 6044742] git-annex in local hub
1 file changed, 1 insertion(+)
create mode 120000 mtree
ok
$ ls -l
total 9
lrwxrwxrwx 1 jgoerzen jgoerzen 178 Jun 15 22:31 mtree -> .git/annex/objects/pX/ZJ/...
OK! We've added a file, and it got transformed into a symlink. That's the thing I said we were going to avoid, so:
git annex adjust --unlock-present
adjust
Switched to branch 'adjusted/main(unlockpresent)'
ok
$ ls -l
total 1
-rw-r--r-- 2 jgoerzen jgoerzen 0 Jun 15 22:31 mtree
You'll notice it transformed into a hard link (nlinks=2) file. Great! Now let's import the source data. For that, we'll use the directory special remote.
$ git annex initremote source type=directory directory=$SOURCEDIR importtree=yes \
encryption=none
initremote source ok
(recording state in git...)
$ git annex enableremote source directory=$SOURCEDIR
enableremote source ok
(recording state in git...)
$ git config remote.source.annex-readonly true
$ git config annex.securehashesonly true
$ git config annex.genmetadata true
$ git config annex.diskreserve 100M
$ git config remote.source.annex-tracking-branch main:$REPONAME
OK, so here we created a new remote named "source". We enabled it, and set some configuration. Most notably, that last line causes files from "source" to be imported under $REPONAME/ as we wanted earlier. Now we're ready to scan the source.
$ git annex sync
At this point, you'll see git-annex computing a hash for every file in the source directory.
I can verify with du that my metadata-only repo only uses 14MB of disk space, while my source is around 4GB.
Now we can see what git-annex thinks about file locations:
$ git-annex whereis less
whereis mtree (1 copy)
8aed01c5-da30-46c0-8357-1e8a94f67ed6 -- local hub [here]
ok
whereis testdata/[redacted] (0 copies)
The following untrusted locations may also have copies:
9e48387e-b096-400a-8555-a3caf5b70a64 -- [source]
failed
... many more lines ...
So remember we said we wanted mtree, but nothing under testdata, under this repo? That's exactly what we got. git-annex knows that the files under testdata can be found under the "source" special remote, but aren't in any git-annex repo -- yet. Now we'll start adding them.
Walkthrough: removable drives
I've set up two 500MB filesystems to represent removable drives. We'll see how git-annex works with them.
$ cd $DRIVE01
$ df -h .
Filesystem Size Used Avail Use% Mounted on
acrypt/no-backup/annexdrive01 500M 1.0M 499M 1% /acrypt/no-backup/annexdrive01
$ git clone $METAREPO
Cloning into 'testdata'...
done.
$ cd $REPONAME
$ git config annex.thin true
$ git annex init "test drive #1"
$ git annex adjust --hide-missing --unlock
adjust
Switched to branch 'adjusted/main(hidemissing-unlocked)'
ok
$ git annex sync
OK, that's the initial setup. Now let's enable the source remote and configure it the same way we did before:
$ git annex enableremote source directory=$SOURCEDIR
enableremote source ok
(recording state in git...)
$ git config remote.source.annex-readonly true
$ git config remote.source.annex-tracking-branch main:$REPONAME
$ git config annex.securehashesonly true
$ git config annex.genmetadata true
$ git config annex.diskreserve 100M
Now, we'll add the drive to a group called "driveset01" and configure what we want on it:
$ git annex group . driveset01
$ git annex wanted . '(not copies=driveset01:1)'
What this does is say: first of all, this drive is in a group named driveset01. Then, this drive wants any files for which there isn't already at least one copy in driveset01.
Now let's load up some files!
$ git annex sync --content
As the messages fly by from here, you'll see it mentioning that it got mtree, and then various files from "source" -- until, that is, the filesystem had less than 100MB free, at which point it complained of no space for the rest. Exactly like we wanted!
Now, we need to teach $METAREPO about $DRIVE01.
$ cd $METAREPO
$ git remote add drive01 $DRIVE01/$REPONAME
$ git annex sync drive01
git-annex sync will change default behavior to operate on --content in a future version of git-annex. Recommend you explicitly use --no-content (or -g) to prepare for that change. (Or you can configure annex.synccontent)
commit
On branch adjusted/main(unlockpresent)
nothing to commit, working tree clean
ok
merge synced/main (Merging into main...)
Updating d1d9e53..817befc
Fast-forward
(Merging into adjusted branch...)
Updating 7ccc20b..861aa60
Fast-forward
ok
pull drive01
remote: Enumerating objects: 214, done.
remote: Counting objects: 100% (214/214), done.
remote: Compressing objects: 100% (95/95), done.
remote: Total 110 (delta 6), reused 0 (delta 0), pack-reused 0
Receiving objects: 100% (110/110), 13.01 KiB 1.44 MiB/s, done.
Resolving deltas: 100% (6/6), completed with 6 local objects.
From /acrypt/no-backup/annexdrive01/testdata
* [new branch] adjusted/main(hidemissing-unlocked) -> drive01/adjusted/main(hidemissing-unlocked)
* [new branch] adjusted/main(unlockpresent) -> drive01/adjusted/main(unlockpresent)
* [new branch] git-annex -> drive01/git-annex
* [new branch] main -> drive01/main
* [new branch] synced/main -> drive01/synced/main
ok
OK! This step is important, because drive01 and drive02 (which we'll set up shortly) won't necessarily be able to reach each other directly, due to not being plugged in simultaneously. Our $METAREPO, however, will know all about where every file is, so that the "wanted" settings can be correctly resolved. Let's see what things look like now:
$ git annex whereis less
whereis mtree (2 copies)
8aed01c5-da30-46c0-8357-1e8a94f67ed6 -- local hub [here]
b46fc85c-c68e-4093-a66e-19dc99a7d5e7 -- test drive #1 [drive01]
ok
whereis testdata/[redacted] (1 copy)
b46fc85c-c68e-4093-a66e-19dc99a7d5e7 -- test drive #1 [drive01] The following untrusted locations may also have copies:
9e48387e-b096-400a-8555-a3caf5b70a64 -- [source]
ok
If I scroll down a bit, I'll see the files past the 400MB mark that didn't make it onto drive01. Let's add another example drive!
Walkthrough: Adding a second drive
The steps for $DRIVE02 are the same as we did before, just with drive02 instead of drive01, so I'll omit listing it all a second time. Now look at this excerpt from whereis:
whereis testdata/[redacted] (1 copy)
b46fc85c-c68e-4093-a66e-19dc99a7d5e7 -- test drive #1 [drive01]
The following untrusted locations may also have copies:
9e48387e-b096-400a-8555-a3caf5b70a64 -- [source]
ok
whereis testdata/[redacted] (1 copy)
c4540343-e3b5-4148-af46-3f612adda506 -- test drive #2 [drive02]
The following untrusted locations may also have copies:
9e48387e-b096-400a-8555-a3caf5b70a64 -- [source]
ok
Look at that! Some files on drive01, some on drive02, some neither place. Perfect!
Walkthrough: Updates
So I've made some changes in the source directory: moved a file, added another, and deleted one. All of these were copied to drive01 above. How do we handle this?
First, we update the metadata repo:
$ cd $METAREPO
$ git annex sync
$ git annex dropunused all
OK, this has scanned $SOURCEDIR and noted changes. Let's see what whereis says:
$ git annex whereis less
...
whereis testdata/cp (0 copies)
The following untrusted locations may also have copies:
9e48387e-b096-400a-8555-a3caf5b70a64 -- [source]
failed
whereis testdata/file01-unchanged (1 copy)
b46fc85c-c68e-4093-a66e-19dc99a7d5e7 -- test drive #1 [drive01] The following untrusted locations may also have copies:
9e48387e-b096-400a-8555-a3caf5b70a64 -- [source]
ok
So this looks right. The file I added was a copy of /bin/cp. I moved another file to one named file01-unchanged. Notice that it realized this was a rename and that the data still exists on drive01.
Well, let's update drive01.
$ cd $DRIVE01/$REPONAME
$ git annex sync --content
Looking at the testdata/ directory now, I see that file01-unchanged has been renamed, the deleted file is gone, but cp isn't yet here -- probably due to space issues; as it's new, it's undefined whether it or some other file would fill up free space. Let's work along a few more commands.
$ git annex get --auto
$ git annex drop --auto
$ git annex dropunused all
And now, let's make sure metarepo is updated with its state.
$ cd $METAREPO
$ git annex sync
We could do the same for drive02. This is how we would proceed with every update.
Walkthrough: Restoration
Now, we have bare files at reasonable locations in drive01 and drive02. But, to generate a consistent restore, we need to be able to actually do an export. Otherwise, we may have files with old names, duplicate files, etc. Let's assume that we lost our source and metadata repos and have to restore from scratch. We'll make a new $RESTOREDIR. We'll begin with drive01 since we used it most recently.
$ mv $METAREPO $METAREPO.disabled
$ mv $SOURCEDIR $SOURCEDIR.disabled
$ git clone $DRIVE01/$REPONAME $RESTOREDIR
$ cd $RESTOREDIR
$ git config annex.thin true
$ git annex init "restore"
$ git annex adjust --hide-missing --unlock
Now, we need to connect the drive01 and pull the files from it.
$ git remote add drive01 $DRIVE01/$REPONAME
$ git annex sync --content
Now, repeat with drive02:
$ git remote add drive02 $DRIVE02/$REPONAME
$ git annex sync --content
Now we've got all our content back! Here's what whereis looks like:
whereis testdata/file01-unchanged (3 copies)
3d663d0f-1a69-4943-8eb1-f4fe22dc4349 -- restore [here]
9e48387e-b096-400a-8555-a3caf5b70a64 -- source
b46fc85c-c68e-4093-a66e-19dc99a7d5e7 -- test drive #1 [origin]
ok
...
I was a little surprised that drive01 didn't seem to know what was on drive02. Perhaps that could have been remedied by adding more remotes there? I'm not entirely sure; I'd thought would have been able to do that automatically.
Conclusions
I think I have demonstrated two things:
First, git-annex is indeed an extremely powerful tool. I have only scratched the surface here. The location tracking is a neat feature, and being able to just access the data as plain files if all else fails is nice for future users.
Secondly, it is also a complex tool and difficult to get right for this purpose (I think much easier for some other purposes). For someone that doesn't live and breathe git-annex, it can be hard to get right. In fact, I'm not entirely sure I got it right here. Why didn't drive02 know what files were on drive01 and vice-versa? I don't know, and that reflects some kind of misunderstanding on my part about how metadata is synced; perhaps more care needs to be taken in restore, or done in a different order, than I proposed. I initially tried to do a restore by using git annex export to a directory special remote with exporttree=yes, but I couldn't ever get it to actually do anything, and I don't know why.
These two cut against each other. On the one hand, the raw accessibility of the data to someone with no computer skills is unmatched. On the other hand, I'm not certain I have the skill to always prepare the discs properly, or to do a proper consistent restore.
Just a few days back we came to know about the horrific Train Crash that happened in Odisha (Orissa). There are some things that are known and somethings that can be inferred by observance. Sadly, it seems the incident is going to be covered up . Some of the facts that have not been contested in the public domain are that there were three lines. One loop line on which the Goods Train was standing and there was an up and a down line. So three lines were there. Apparently, the signalling system and the inter-locking system had issues as highlighted by an official about a month back. That letter, thankfully is in the public domain and I have downloaded it as well. It s a letter that goes to 4 pages. The RW is incensed that the letter got leaked and is in public domain. They are blaming everyone and espousing conspiracy theories rather than taking the minister to task. Incidentally, the Minister has three ministries that he currently holds. Ministry of Communication, Ministry of Electronics and Information Technology (MEIT), and Railways Ministry. Each Ministry in itself is important and has revenues of more than 6 lakh crore rupees. How he is able to do justice to all the three ministries is beyond me
The other thing is funds both for safety and relaying of tracks has been either not sanctioned or unutilized. In fact, CAG and the Railway Brass had shared how derailments have increased and unfulfilled vacancies but they were given no importance In fact, not talking about safety in the recently held Chintan Shivir (brainstorming session) tells you how much the Govt. is serious about safety. In fact, most of the programme was on high speed rail which is a white elephant. I have shared a whitepaper done by RW in the U.S. that tells how high-speed rail doesn t make economic sense. And that is an economy that is 20 times + the Indian Economy. Even the Chinese are stopping with HSR as it doesn t make economic sense.
Incidentally, Air Fares again went up 200% yesterday. Somebody shared in the region of 20k + for an Air ticket from their place to Bangalore
Coming back to the story itself. the Goods Train was on the loopline. Some say it was a little bit on the outer, some say otherwise, but it is established that it was on the loopline. This is standard behavior on and around Railway Stations around the world. Whether it was in the Inner or Outer doesn t make much of a difference with what happened next. The first train that collided with the goods train was the 12864 (SMVB-HWH) Yashwantpur Howrah Express and got derailed on to the next track where from the opposite direction 12841 (Shalimar- Bangalore) Coramandel Express was coming. Now they have said that around 300 people have died and that seems to be part of the cover-up. Both the trains are long trains, having between 23 odd coaches each. Even if you have reserved tickets you have 80 odd people in a coach and usually in most of these trains, it is at least double of that. Lot of money goes to TC and then above (Corruption). The Railway fares have gone up enormously but that s a question for perhaps another time . So at the very least, we could be looking at more than 1000 people having died. The numbers are being under-reported so that nobody has to take responsibility. The Railways itself has told that it is unable to identify 80% of the people who have died. This means that 80% were unreserved ticket holders or a majority of them. There have been disturbing images as how bodies have been flung over on tractors and whatnot to be either buried or cremated without a thought. We are in peak summer season so bodies will start to rot within 24-48 hours No arrangements made to cool the bodies and take some information and identifying marks or whatever. The whole thing being done in a very callous manner, not giving dignity to even those who have died for no fault of their own. The dissent note also tells that a cover-up is also in the picture. Apparently, India doesn t have nor does it feel to have a need for something like the NTSB that the U.S. used when it hauled both the plane manufacturer (Boeing) and the FAA when the 737 Max went down due to improper data collection and sharing of data with pilots. And with no accountability being fixed to Minister or any of the senior staff, a small junior staff person may be fired. Perhaps the same official that actually told them about the signal failures almost 3 months back
There were and are also some reports that some jugaadu /temporary fixes were applied to signalling and inter-locking just before this incident happened. I do not know nor confirm one way or the other if the above happened. I can however point out that if such a thing happened, then usually a traffic block is announced and all traffic on those lines are stopped. This has been the thing I know for decades. Traveling between Mumbai and Pune multiple times over the years am aware about traffic block. If some repair work was going on and it wasn t able to complete the work within the time-frame then that may well have contributed to the accident. There is also a bit muddying of the waters where it is being said that one of the trains was 4 hours late, which one is conflicting stories.
On top of the whole thing, they have put the case to be investigated by CBI and hinting at sabotage. They also tried to paint a religious structure as mosque, later turned out to be a temple. The RW says done by Muslims as it was Friday not taking into account as shared before that most Railway maintenance works are usually done between Friday Monday. This is a practice followed not just in India but world over.
There has been also move over a decade to remove wooden sleepers and have concrete sleepers. Unlike the wooden ones they do not expand and contract as much and their life is much more longer than the wooden ones. Funds had been marked (although lower than last few years) but not yet spent. As we know in case of any accident, it is when all the holes in cheese line up it happens. Fukushima is a great example of that, no sea wall even though Japan is no stranger to Tsunamis. External power at the same level as the plant. (10 meters above sea-level), no training for cascading failures scenarios which is what happened. The Days mini-series shares some but not all the faults that happened at Fukushima and the Govt. response to it. There is a difference though, the Japanese Prime Minister resigned on moral grounds. Here, nor the PM, nor the Minister would be resigning on moral grounds or otherwise :(. Zero accountability and that was partly a natural disaster, here it s man-made. In fact, both the Minister and the Prime Minister arrived with their entourages, did a PR blitzkrieg showing how concerned they are. Within 50 hours, the lines were cleared. The part-time Railway Minister shared that he knows the root cause and then few hours later has given the case to CBI. All are saying, wait for the inquiry report. To date, none of the accidents even in this Govt. has produced an investigation report. And even if it did, I am sure it will whitewash as it did in case of Adani as I had shared before in the previous blog post. Incidentally, it is reported that Adani paid off some of its debt, but when questioned as to where they got the money, complete silence on that part :(. As can be seen cover-up after cover-up
FWIW, the Coramandel Express is known as the Migrant train so has a huge number of passengers, the other one which was collided with is known as sick train as huge number of cancer patients use it to travel to Chennai and come back
Demonetization 2.0
Few days back, India announced demonetization 2.0. Surprised, don t be. Apparently, INR 2k/- is being used for corruption and Mr. Modi is unhappy about it. He actually didn t like the INR 2k/- note but was told that it was needed, who told him we are unaware to date. At that time the RBI Governor was Mr. Urjit Patel who didn t say about INR 2k/- he had said that INR 1k/- note redesigned would come in the market. That has yet to happen. What has happened is that just like INR 500/- and INR 1k/- note is concerned, RBI will no longer honor the INR 2k/- note. Obviously, this has made our neighbors angry, namely Nepal, Sri Lanka, Bhutan etc. who do some trading with us. 2 Deccan heraldcolumns share the limelight on it. Apparently, India wants to be the world s currency reserve but doesn t want to play by the rules for everyone else. It was pointed out that both the U.S. and Singapore had retired their currencies but they will honor that promise even today. The Singapore example being a bit closer (as it s in Asia) is perhaps a bit more relevant than the U.S. one. Singapore retired the SGD $10,000 as of 2014 but even in 2022, it remains as legal tender. They also retired the SGD $1,000 in 2020 but still remains legal tender.
So let s have a fictitious example to illustrate what is meant by what Singapore has done. Let s say I go to Singapore, rent a flat, and find a $1000 note in that house somewhere. Both practically and theoretically, I could go down to any of the banks, get the amount transferred to my wallet, bank account etc. and nobody will question. Because they have promised the same. Interestingly, the Singapore Dollar has been pretty resilient against the USD for quite a number of years vis-a-vis other Asian currencies.
Most of the INR 2k/- notes were also found and exchanged in Gujarat in just a few days (The PM and HM s state.). I am sure you are looking into the mental gymnastics that the RW indulge in :(. What is sadder that most of the people who try to defend can t make sense one way or the other and start to name-call and get personal as they have nothing else
Disability questions dropped in NHFS-6
Just came to know today that in the upcoming National Family Health Survey-6 disability questions are being dropped. Why is this important. To put it simply, if you don t have numbers, you won t and can t make policies for them. India is one of the worst countries to live if you are disabled. The easiest way to share to draw attention is most Railway platforms are not at level with people. Just as Mick Lynch shares in the UK, the same is pretty much true for India too. Meanwhile in Europe, they do make an effort to be level so even disabled people have some dignity. If your public transport is sorted, then people would want much more and you will be obligated to provide for them as they are citizens. Here, we have had many reports of women being sexually molested when being transferred from platform to coach irrespective of their age or whatnot The main takeaway is if you do not have their voice, you won t make policies for them. They won t go away but you will make life hell for them. One thing to keep in mind that most people assume that most people are disabled from birth. This may or may not be true. For e.g. in the above triple Railways accidents, there are bound to be disabled people or newly disabled people who were healthy before the accident. The most common accident is road accidents, some involving pedestrians and vehicles or both, the easiest is Ministry of Road Transport data that says 4,00,000 people sustained injuries in 2021 alone in road mishaps. And this is in a country where even accidents are highly under-reported, for more than one reason. The biggest reason especially in 2 and 4 wheeler is the increased premium they would have to pay if in an accident, so they usually compromise with the other and pay off the Traffic Inspector.
Sadly, I haven t read a new book, although there are a few books I m looking forward to have. People living in India and neighbors please be careful as more heat waves are expected. Till later.
Hello folks!
We recently received a case letting us know that Dataproc 2.1.1 was unable to write to a BigQuery table with a column of type JSON. Although the BigQuery connector for Spark has had support for JSON columns since 0.28.0, the Dataproc images on the 2.1 line still cannot create tables with JSON columns or write to existing tables with JSON columns.
The customer has graciously granted permission to share the code we developed to allow this operation. So if you are interested in working with JSON column tables on Dataproc 2.1 please continue reading!
Use the following gcloud command to create your single-node dataproc cluster:
The following file is the Scala code used to write JSON structured data to a BigQuery table using Spark. The file following this one can be executed from your single-node Dataproc cluster.
Main.scala
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types. Metadata, StringType, StructField, StructType
import org.apache.spark.sql. Row, SaveMode, SparkSession
import org.apache.spark.sql.avro
import org.apache.avro.specific
val env = "x"
val my_bucket = "cjac-docker-on-yarn"
val my_table = "dataset.testavro2"
val spark = env match
case "local" =>
SparkSession
.builder()
.config("temporaryGcsBucket", my_bucket)
.master("local")
.appName("isssue_115574")
.getOrCreate()
case _ =>
SparkSession
.builder()
.config("temporaryGcsBucket", my_bucket)
.appName("isssue_115574")
.getOrCreate()
// create DF with some data
val someData = Seq(
Row(""" "name":"name1", "age": 10 """, "id1"),
Row(""" "name":"name2", "age": 20 """, "id2")
)
val schema = StructType(
Seq(
StructField("user_age", StringType, true),
StructField("id", StringType, true)
)
)
val avroFileName = s"gs://$ my_bucket /issue_115574/someData.avro"
val someDF = spark.createDataFrame(spark.sparkContext.parallelize(someData), schema)
someDF.write.format("avro").mode("overwrite").save(avroFileName)
val avroDF = spark.read.format("avro").load(avroFileName)
// set metadata
val dfJSON = avroDF
.withColumn("user_age_no_metadata", col("user_age"))
.withMetadata("user_age", Metadata.fromJson(""" "sqlType":"JSON" """))
dfJSON.show()
dfJSON.printSchema
// write to BigQuery
dfJSON.write.format("bigquery")
.mode(SaveMode.Overwrite)
.option("writeMethod", "indirect")
.option("intermediateFormat", "avro")
.option("useAvroLogicalTypes", "true")
.option("table", my_table)
.save()
#!/bin/bash
PROJECT_ID=set-yours-here
DATASET_NAME=dataset
TABLE_NAME=testavro2
# We have to remove all of the existing spark bigquery jars from the local
# filesystem, as we will be using the symbols from the
# spark-3.3-bigquery-0.30.0.jar below. Having existing jar files on the
# local filesystem will result in those symbols having higher precedence
# than the one loaded with the spark-shell.
sudo find /usr -name 'spark*bigquery*jar' -delete
# Remove the table from the bigquery dataset if it exists
bq rm -f -t $PROJECT_ID:$DATASET_NAME.$TABLE_NAME
# Create the table with a JSON type column
bq mk --table $PROJECT_ID:$DATASET_NAME.$TABLE_NAME \
user_age:JSON,id:STRING,user_age_no_metadata:STRING
# Load the example Main.scala
spark-shell -i Main.scala \
--jars /usr/lib/spark/external/spark-avro.jar,gs://spark-lib/bigquery/spark-3.3-bigquery-0.30.0.jar
# Show the table schema when we use bq mk --table and then load the avro
bq query --use_legacy_sql=false \
"SELECT ddl FROM $DATASET_NAME.INFORMATION_SCHEMA.TABLES where table_name='$TABLE_NAME'"
# Remove the table so that we can see that the table is created should it not exist
bq rm -f -t $PROJECT_ID:$DATASET_NAME.$TABLE_NAME
# Dynamically generate a DataFrame, store it to avro, load that avro,
# and write the avro to BigQuery, creating the table if it does not already exist
spark-shell -i Main.scala \
--jars /usr/lib/spark/external/spark-avro.jar,gs://spark-lib/bigquery/spark-3.3-bigquery-0.30.0.jar
# Show that the table schema does not differ from one created with a bq mk --table
bq query --use_legacy_sql=false \
"SELECT ddl FROM $DATASET_NAME.INFORMATION_SCHEMA.TABLES where table_name='$TABLE_NAME'"
Google BigQuery has supported JSON data since October of 2022, but until now, it has not been possible, on generally available Dataproc clusters, to interact with these columns using the Spark BigQuery Connector.
JSON column type support was introduced in spark-bigquery-connector release 0.28.0.
In March and April I worked a total of 28 hours for Freexian's
Debian LTS initiative, out of a maximum of 48 hours.
I updated the linux (4.19) package to the latest stable and
stable-rt updates, and uploaded it at the end of April. I merged
the latest bullseye security update into the linux-5.10 package and
uploaded that at the same time.
This isn't a book review, although the reason that I am typing this now is
because of a book, You Are Not Alone: from the creator and host of
Griefcast, Cariad Lloyd, ISBN: 978-1526621870 and I include a handful of
quotes from Cariad where there is really no better way of describing things.
Many people experience death for the first time as a child, often relating to a
family pet. Death is universal but every experience of death is unique. One of
the myths of grief is the idea of the Five Stages but this is a
misinterpretation. Denial, Anger, Bargaining, Depression and Acceptance
represent the five stage model of death and have nothing to do with
grief. The five stages were developed from studying those who are
terminally ill, the dying, not those who then grieve for the dead person and
have to go on living without them. Grief is for those who loved the person who
has died and it varies between each of those people just as people vary in how
they love someone. The Five Stages end at the moment of death, grief is what
comes next and most people do not grieve in stages, it can be more like a
tangled knot.
Death has a date and time, so that is why the last stage of the model is
Acceptance. Grief has no timetable, those who grieve will carry that grief for
the rest of their lives. Death starts the process of grief in those who go on
living just as it ends the life of the person who is loved. "Grief eases and
changes and returns but it never disappears.".
I suspect many will have already stopped reading by this point. People do not
talk about death and grief enough and this only adds to the burden of those who
carry their grief. It can be of enormous comfort to those who have carried
grief for some time to talk directly about the dead, not in vague pleasantries
but with specific and strong memories. Find a safe place without distractions
and talk with the person grieving face to face. Name the dead person. Go to
places with strong memories and be there alongside. Talk about the times with
that person before their death. Early on, everything about grief is painful and
sad. It does ease but it remains unpredictable. Closing it away in a box inside
your head (as I did at one point) is like cutting off a damaged limb but
keeping the pain in a box on the shelf. You still miss the limb and eventually,
the box starts leaking.
For me, there were family pets which died but my first job out of university
was to work in hospitals, helping the nurses manage the medication regimen and
providing specialist advice as a pharmacist. It will not be long in that
environment before everyone on the ward gets direct experience of the death of
a person. In some ways, this helped me to separate the process of death from
the process of grief. I cared for these people as patients but these were not
my loved ones. Later, I worked in specialist terminal care units, including
providing potential treatments as part of clinical trials. Here, it was not
expected for any patient to be discharged alive. The more aggressive
chemotherapies had already been tried and had failed, this was about pain
relief, symptom management and helping the loved ones. Palliative care is not
just about the patient, it involves helping the loved ones to accept what is
happening as this provides comfort to the patient by closing the loop.
Grief is stressful. One of the most common causes of personal stress is
bereavement.
The death of your loved one is outside of your control, it has happened, no
amount of regret can change that. Then come all the other stresses, maybe about
money or having somewhere to live as a result of what else has changed after
the death or having to care for other loved ones.
In the early stages, the first two years, I found it helpful to imagine my life
as a box containing a ball and a button. The button triggers new waves of pain
and loss each time it is hit. The ball bounces around the box and hits the
button at random. Initially, the button is large and the ball is enormous, so
the button is hit almost constantly. Over time, both the button and the ball
change size. Starting off at maximum, initially there is only one direction of
change. There are two problems with this analogy. First is that the grief ball
has infinite energy which does not happen in reality. The ball may get smaller
and the button harder to hit but the ball will continue bouncing. Secondly, the
life box is not a predictable shape, so the pattern of movement of the ball is
unpredictable.
A single stress is one thing, but what has happened since has just kept adding
more stress for me. Shortly before my father died 5 years ago now, I had moved
house. Then, I was made redundant on the day of the first anniversary of my
father's death. A year or so later, my long term relationship failed and a few
months after that COVID-19 appeared. As the country eased out of the pandemic
in 2021, my mother died (unrelated to COVID itself). A year after that, I had
to take early retirement. My brother and sister, of course, share a lot of
those stressors. My brother, in particular, took the responsibility for
organising both funerals and did most of the visits to my mother before her
death. The grief is different for each of the surviving family.
Cariad's book helped me understand why I was getting frequent ideas about going
back to visit places which my father and I both knew. My parents encouraged
each of us to work hard to leave Port Talbot (or Pong Toilet locally) behind,
in no small part due to the unrestrained pollution and deprivation that is
common to small industrial towns across Wales, the midlands and the north of
the UK. It wasn't that I wanted to move house back to our ancestral roots. It
was my grief leaking out of the box. Yes, I long for mountains and the sea
because I'm now living in a remorselessly flat and landlocked region after
moving here for employment. However, it was my grief driving those longings -
not for the physical surroundings but out of the shared memories with my
father. I can visit those memories without moving house, I just need to arrange
things so that I can be undisturbed and undistracted.
I am not alone with my grief and I am grateful to my friends who have helped
whilst carrying their own grief. It is necessary for everyone to think and talk
about death and grief. In respect of your own death, no matter how far ahead
that may be, consider Advance Care Planning and Expressions of Wish as well
as your Will.
Help your loved ones cope with your death by describing what you would like
to happen.
Document how your life has been arranged so that the executor of your Will
can find the right documents to inform:
your bank,
your mortgage company,
your energy company,
your mobile phone company,
your house and car insurers and the like.
If you've got a complex home setup with servers and other machines which
would be unfamiliar to the executor of your Will, then entrust someone else
with the information required to revoke your keys, access your machines etc.
and then provide the contact information for that person to your executor.
Arrange for your pets to be looked after.
Describe how you would like your belongings to be handled - do you want every
effort made to have your clothes and furnishing recycled instead of going to
landfill?
Where are the documents for the oven, the dishwasher and the central heating
system so that these can be included in the sale of your property?
If there are loans outstanding, make sure your executor or a trusted person
knows where to find the account numbers and company names.
What about organ donation? Make sure your executor knows your wishes and
make sure your loved ones either agree or are willing to respect your wishes.
Then the personal stuff, what do you want to happen to your social media
accounts, your cloud data, your games, DVD and CD collection, your photos and
other media? Some social media companies have explicit settings available in
your account to describe if you want the data deleted after a certain amount
of time, after a notification from some government service or to set up some
kind of memorialised version or hand over control of the account to a trusted
person.
Talk to people, document what you want. Your loved ones will be grateful and
they deserve that much whilst they try to cope with the first onslaught of
grief. Talk to your loved ones and get them to do the same for themselves.
Normalise talking about death with your family, especially children. None of us
are getting out of this alive and we will all leave behind people who will
grieve.

 QNAP TS-453mini product photo
QNAP TS-453mini product photo The logo for QNAP HappyGet 2 and Blizzard s StarCraft 2 side by side
The logo for QNAP HappyGet 2 and Blizzard s StarCraft 2 side by side Thermalright AXP120-X67, AMD Ryzen 5 PRO 5650GE, ASRock Rack X570D4I-2T, all assembled and running on a flat surface
Thermalright AXP120-X67, AMD Ryzen 5 PRO 5650GE, ASRock Rack X570D4I-2T, all assembled and running on a flat surface Memtest86 showing test progress, taken from IPMI remote control window
Memtest86 showing test progress, taken from IPMI remote control window Screenshot of PCIe 16x slot bifurcation options in UEFI settings, taken from IPMI remote control window
Screenshot of PCIe 16x slot bifurcation options in UEFI settings, taken from IPMI remote control window Internal image of Silverstone CS280 NAS build. Image stolen from ServeTheHome
Internal image of Silverstone CS280 NAS build. Image stolen from ServeTheHome Internal image of Silverstone CS280 NAS build. Image stolen from ServeTheHome
Internal image of Silverstone CS280 NAS build. Image stolen from ServeTheHome NAS build in Silverstone SUGO 14, mid build, panels removed
NAS build in Silverstone SUGO 14, mid build, panels removed Silverstone SUGO 14 from the front, with hot swap bay installed
Silverstone SUGO 14 from the front, with hot swap bay installed Storage SSD loaded into hot swap sled
Storage SSD loaded into hot swap sled TrueNAS Dashboard screenshot in browser window
TrueNAS Dashboard screenshot in browser window The final system, powered up
The final system, powered up I dug out a computer running Fedora 28, which was released 2018-04-01 - over 5 years ago. Backing up the data and re-installing seemed tedious, but the current version of Fedora is 38, and while Fedora supports updates from N to N+2 that was still going to be 5 separate upgrades. That seemed tedious, so I figured I'd just try to do an update from 28 directly to 38. This is, obviously, extremely unsupported, but what could possibly go wrong?
I dug out a computer running Fedora 28, which was released 2018-04-01 - over 5 years ago. Backing up the data and re-installing seemed tedious, but the current version of Fedora is 38, and while Fedora supports updates from N to N+2 that was still going to be 5 separate upgrades. That seemed tedious, so I figured I'd just try to do an update from 28 directly to 38. This is, obviously, extremely unsupported, but what could possibly go wrong? KDE Akademy 2023
KDE Akademy 2023 KDE Konsole snap
KDE Konsole snap This post describes how to deploy
This post describes how to deploy 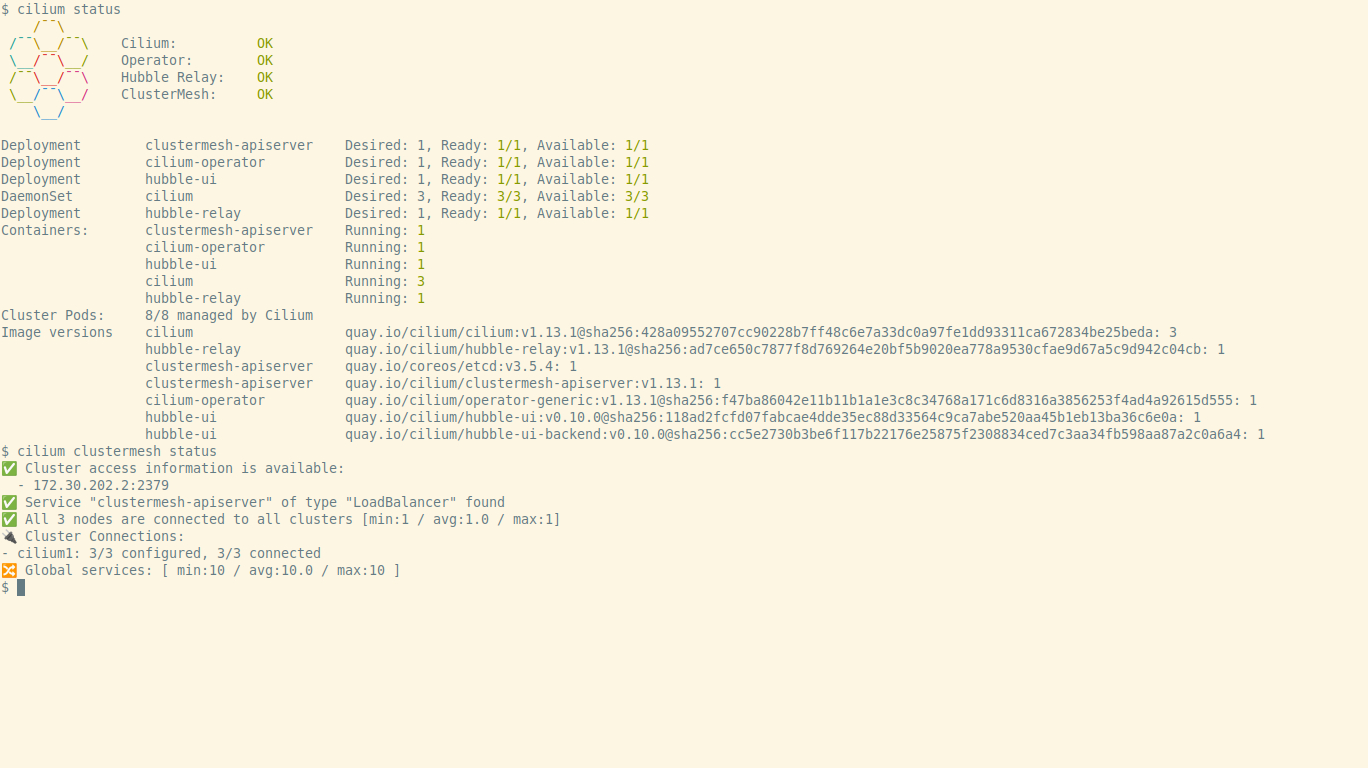

 Something that can never be fixed
Something that can never be fixed  I have had the pleasure to have Poha in many ways. One of my favorite ones is when people have actually put tadka on top of Poha. You do everything else but in a slight reverse order. The tadka has all the spices mixed and is concentrated and is put on top of Poha and then mixed. Done right, it tastes out of this world. For those who might not have had the Indian culinary experience, most of which is actually borrowed from the Mughals, you are in for a treat.
One of the other things I would suggest to people is to ask people where there can get five types of rice. This is a specialty of South India and a sort of street food. I know where you can get it Hyderabad, Bangalore, Chennai but not in Kerala, although am dead sure there is, just somehow have missed it. If asked, am sure the Kerala team should be able to guide.
That s all for now, feeling hungry, having dinner as have been sharing about cooking.
I have had the pleasure to have Poha in many ways. One of my favorite ones is when people have actually put tadka on top of Poha. You do everything else but in a slight reverse order. The tadka has all the spices mixed and is concentrated and is put on top of Poha and then mixed. Done right, it tastes out of this world. For those who might not have had the Indian culinary experience, most of which is actually borrowed from the Mughals, you are in for a treat.
One of the other things I would suggest to people is to ask people where there can get five types of rice. This is a specialty of South India and a sort of street food. I know where you can get it Hyderabad, Bangalore, Chennai but not in Kerala, although am dead sure there is, just somehow have missed it. If asked, am sure the Kerala team should be able to guide.
That s all for now, feeling hungry, having dinner as have been sharing about cooking.
 Last weekend was the bi-annual time to roll the main machine and
server to the current Ubuntu release, now at 23.04. It must now have
been fifteen or so years that I have used Ubuntu for my desktop / server
(for reasons I may write about another time). And of course it all
passed swimmingly as usual.
[ And a small aside, if I may. Among all these upgrades, one of my
favourite piece of tech trivia that may well be too little known remains
the dedication of the PostgreSQL maintainers installing the new version,
now PostgreSQL 15, seamlessly in parallel with the existing one, in my
case PostgreSQL 14, keeping both running (!!) on two neighbouring ports
(!!) so that there is no service disruption. So at some point, maybe
this weekend, I will run the provided script to dump-and-restore to
trigger the database migration at my convenience. Happy PostgreSQL on
Debian/Ubuntu user since the late 1990s. It. Just. Works. ]
[ Similarly, it is plainly amazeballs how
Last weekend was the bi-annual time to roll the main machine and
server to the current Ubuntu release, now at 23.04. It must now have
been fifteen or so years that I have used Ubuntu for my desktop / server
(for reasons I may write about another time). And of course it all
passed swimmingly as usual.
[ And a small aside, if I may. Among all these upgrades, one of my
favourite piece of tech trivia that may well be too little known remains
the dedication of the PostgreSQL maintainers installing the new version,
now PostgreSQL 15, seamlessly in parallel with the existing one, in my
case PostgreSQL 14, keeping both running (!!) on two neighbouring ports
(!!) so that there is no service disruption. So at some point, maybe
this weekend, I will run the provided script to dump-and-restore to
trigger the database migration at my convenience. Happy PostgreSQL on
Debian/Ubuntu user since the late 1990s. It. Just. Works. ]
[ Similarly, it is plainly amazeballs how  Hello folks!
We recently received a case letting us know that Dataproc 2.1.1 was unable to write to a BigQuery table with a column of type JSON. Although the BigQuery connector for Spark has had support for JSON columns since 0.28.0, the Dataproc images on the 2.1 line still cannot create tables with JSON columns or write to existing tables with JSON columns.
The customer has graciously granted permission to share the code we developed to allow this operation. So if you are interested in working with JSON column tables on Dataproc 2.1 please continue reading!
Use the following gcloud command to create your single-node dataproc cluster:
Hello folks!
We recently received a case letting us know that Dataproc 2.1.1 was unable to write to a BigQuery table with a column of type JSON. Although the BigQuery connector for Spark has had support for JSON columns since 0.28.0, the Dataproc images on the 2.1 line still cannot create tables with JSON columns or write to existing tables with JSON columns.
The customer has graciously granted permission to share the code we developed to allow this operation. So if you are interested in working with JSON column tables on Dataproc 2.1 please continue reading!
Use the following gcloud command to create your single-node dataproc cluster:
 In March and April I worked a total of 28 hours for Freexian's
Debian LTS initiative, out of a maximum of 48 hours.
I updated the linux (4.19) package to the latest stable and
stable-rt updates, and uploaded it at the end of April. I merged
the latest bullseye security update into the linux-5.10 package and
uploaded that at the same time.
In March and April I worked a total of 28 hours for Freexian's
Debian LTS initiative, out of a maximum of 48 hours.
I updated the linux (4.19) package to the latest stable and
stable-rt updates, and uploaded it at the end of April. I merged
the latest bullseye security update into the linux-5.10 package and
uploaded that at the same time.
 This isn't a book review, although the reason that I am typing this now is
because of a book, You Are Not Alone: from the creator and host of
Griefcast, Cariad Lloyd, ISBN: 978-1526621870 and I include a handful of
quotes from Cariad where there is really no better way of describing things.
Many people experience death for the first time as a child, often relating to a
family pet. Death is universal but every experience of death is unique. One of
the myths of grief is the idea of the Five Stages but this is a
misinterpretation. Denial, Anger, Bargaining, Depression and Acceptance
represent the five stage model of death and have nothing to do with
grief. The five stages were developed from studying those who are
terminally ill, the dying, not those who then grieve for the dead person and
have to go on living without them. Grief is for those who loved the person who
has died and it varies between each of those people just as people vary in how
they love someone. The Five Stages end at the moment of death, grief is what
comes next and most people do not grieve in stages, it can be more like a
tangled knot.
Death has a date and time, so that is why the last stage of the model is
Acceptance. Grief has no timetable, those who grieve will carry that grief for
the rest of their lives. Death starts the process of grief in those who go on
living just as it ends the life of the person who is loved. "Grief eases and
changes and returns but it never disappears.".
I suspect many will have already stopped reading by this point. People do not
talk about death and grief enough and this only adds to the burden of those who
carry their grief. It can be of enormous comfort to those who have carried
grief for some time to talk directly about the dead, not in vague pleasantries
but with specific and strong memories. Find a safe place without distractions
and talk with the person grieving face to face. Name the dead person. Go to
places with strong memories and be there alongside. Talk about the times with
that person before their death. Early on, everything about grief is painful and
sad. It does ease but it remains unpredictable. Closing it away in a box inside
your head (as I did at one point) is like cutting off a damaged limb but
keeping the pain in a box on the shelf. You still miss the limb and eventually,
the box starts leaking.
For me, there were family pets which died but my first job out of university
was to work in hospitals, helping the nurses manage the medication regimen and
providing specialist advice as a pharmacist. It will not be long in that
environment before everyone on the ward gets direct experience of the death of
a person. In some ways, this helped me to separate the process of death from
the process of grief. I cared for these people as patients but these were not
my loved ones. Later, I worked in specialist terminal care units, including
providing potential treatments as part of clinical trials. Here, it was not
expected for any patient to be discharged alive. The more aggressive
chemotherapies had already been tried and had failed, this was about pain
relief, symptom management and helping the loved ones. Palliative care is not
just about the patient, it involves helping the loved ones to accept what is
happening as this provides comfort to the patient by closing the loop.
Grief is stressful. One of the most common
This isn't a book review, although the reason that I am typing this now is
because of a book, You Are Not Alone: from the creator and host of
Griefcast, Cariad Lloyd, ISBN: 978-1526621870 and I include a handful of
quotes from Cariad where there is really no better way of describing things.
Many people experience death for the first time as a child, often relating to a
family pet. Death is universal but every experience of death is unique. One of
the myths of grief is the idea of the Five Stages but this is a
misinterpretation. Denial, Anger, Bargaining, Depression and Acceptance
represent the five stage model of death and have nothing to do with
grief. The five stages were developed from studying those who are
terminally ill, the dying, not those who then grieve for the dead person and
have to go on living without them. Grief is for those who loved the person who
has died and it varies between each of those people just as people vary in how
they love someone. The Five Stages end at the moment of death, grief is what
comes next and most people do not grieve in stages, it can be more like a
tangled knot.
Death has a date and time, so that is why the last stage of the model is
Acceptance. Grief has no timetable, those who grieve will carry that grief for
the rest of their lives. Death starts the process of grief in those who go on
living just as it ends the life of the person who is loved. "Grief eases and
changes and returns but it never disappears.".
I suspect many will have already stopped reading by this point. People do not
talk about death and grief enough and this only adds to the burden of those who
carry their grief. It can be of enormous comfort to those who have carried
grief for some time to talk directly about the dead, not in vague pleasantries
but with specific and strong memories. Find a safe place without distractions
and talk with the person grieving face to face. Name the dead person. Go to
places with strong memories and be there alongside. Talk about the times with
that person before their death. Early on, everything about grief is painful and
sad. It does ease but it remains unpredictable. Closing it away in a box inside
your head (as I did at one point) is like cutting off a damaged limb but
keeping the pain in a box on the shelf. You still miss the limb and eventually,
the box starts leaking.
For me, there were family pets which died but my first job out of university
was to work in hospitals, helping the nurses manage the medication regimen and
providing specialist advice as a pharmacist. It will not be long in that
environment before everyone on the ward gets direct experience of the death of
a person. In some ways, this helped me to separate the process of death from
the process of grief. I cared for these people as patients but these were not
my loved ones. Later, I worked in specialist terminal care units, including
providing potential treatments as part of clinical trials. Here, it was not
expected for any patient to be discharged alive. The more aggressive
chemotherapies had already been tried and had failed, this was about pain
relief, symptom management and helping the loved ones. Palliative care is not
just about the patient, it involves helping the loved ones to accept what is
happening as this provides comfort to the patient by closing the loop.
Grief is stressful. One of the most common